Introduction
Lors de mes débuts dans Spark, un collègue m’a dit la chose suivante : "N’utilise pas groupByKey, utilise plutôt reduceByKey". Je lui demande alors pourquoi l’un plutôt que l’autre et il me répond tout simplement : “à cause du shuffle”. Hein ? Shuffle ?


Effectivement, je n’avais encore jamais entendu ce terme dans ma vie, alors qu’il se révèle d’une importance extrême dans le traitement des données en parallèle, surtout si vous voulez avoir une performance élevée dans vos temps de traitement.
Qu’est-ce que le shuffle dans Spark ?
Shuffle (anglais) : remanier, mélanger, battre (des cartes)...
Dans Spark, on parle de shuffle lorsqu’on envoie des données à travers le cluster, d’une machine vers une autre. Par exemple :
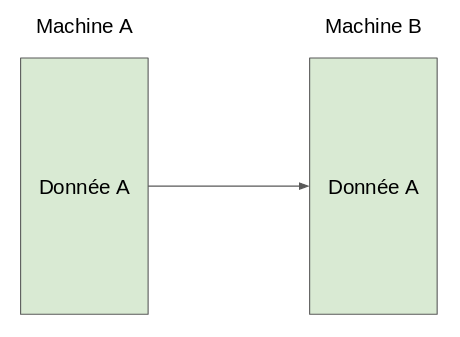
On effectue un shuffle de la donnée A et on l'envoie de la machine A vers la machine B. Simple non ?
La chose importante à retenir est que ce transfert de données requiert une connexion réseau entre les machines, et que plus il y aura de machines et de données à transférer, plus il y aura de trafic réseau.
Et donc c’est quoi la différence entre groupByKey et reduceByKey ?
Tout d’abord, rafraîchissons nous la mémoire sur les “resilient distributed dataset”, plus communément appelés RDD. Spark Core travaille avec ces objets, qui sont des collections de records/observations distribuées dans un cluster de machines. Chaque “morceau” de RDD réparti est appelé partition. Dans Spark, chacune des partitions appartient à un exécuteur.
Exemple de construction d’un RDD :
val words =
List("univalence", "scala", "scala", "univalence", "univalence", "scala")
val wordsRDD = sc.parallelize(words).map(word => (word, 1))Afin de pouvoir observer la différence entre groupByKey et reduceByKey, essayons de les appliquer au RDD du dessus pour faire un simple word count (occurrence de chaque string d’une liste).
// Code groupByKey
val wordCountGroupByKey = wordsRDD
.groupByKey() // On groupe chaque paire par leur clé (ici le mot)
.map((word, list) => (word, list.sum)) // On fait la somme// Code reducebykey
val wordCountReduceByKey = wordsRDD
.reduceByKey(_ + _) // On calcule l’occurrence et groupe chaque paire
// par leur cléLes deux fonctions ont à priori l’air de faire le même travail, bien qu’ils s’appliquent différemment. Pourtant, reduceByKey est en fait plus performant que groupByKey lorsqu’il y a beaucoup de données (et ça c’est utile quand on travaille dans le Big Data).
But why ?
Imaginons que le RDD wordsRDD est réparti en deux partitions.

En réalité, ce qui se passe pour groupByKey, c’est qu’il va d’abord chercher à déplacer les clés identiques dans une même partition (1), afin de pouvoir appliquer le traitement (2) (ici faire la somme pour chaque mot) :
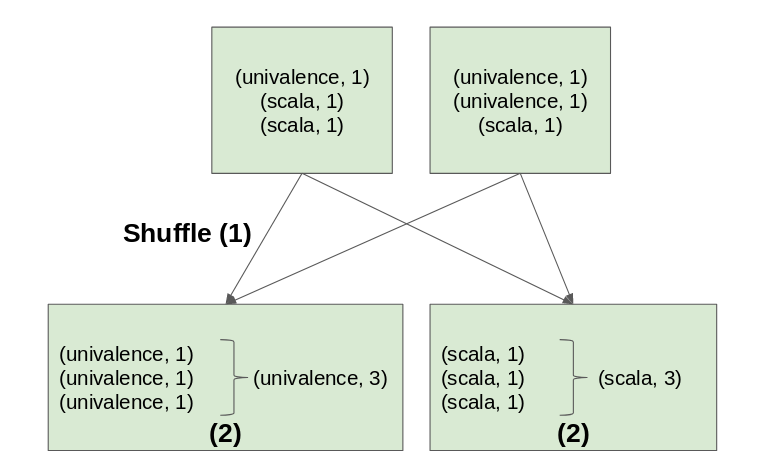
Il y a deux conséquences à cela :
- Cela produit un shuffle assez important des données car il doit le faire pour chaque donnée de chaque partition du RDD. Donc, si les partitions ne sont pas sur une même machine, cela provoque un gros trafic réseau.
- Si dans notre exemple un mot composait 99% de la liste, groupByKey rassemblera toutes les données ayant comme clé ce mot dans une seule machine, ce qui peut causer des problèmes de mémoire.
Pour reduceByKey, les choses se passent différemment. Il y a d’abord un “pré-traitement” (1) dans chacune des partitions, puis les données sont déplacées selon leur clé (2), pour enfin avoir un traitement final (3) sur les partitions :

On n’évite donc pas le shuffle de données avec reduceByKey. Néanmoins la quantité de données à déplacer est amoindrie par le pré-traitement dans chaque partition. Il en résulte un trafic réseau potentiellement moins important (donc amélioration du temps de traitement) et également moins de risque de problème de mémoire.
Conclusion
- Prendre en compte le shuffle lorsque des traitements parallèles sont mis en place, notamment les opérations comme
reduceByKeyetgroupByKeyqui en produisent. - Préférer
reduceByKeyàgroupByKeypour avoir une meilleure performance dans le temps de traitement et moins de problèmes de mémoire (en particulier si le nombre moyen d'éléments par clé par partition est élevé). - Si vous voulez aller plus loin il y a
combineByKeyqui offre encore plus d'options (reduceByKeyest implémenté en utilisantcombineByKey)