Intention
Imaginez que vous disposez de deux flux : l'un représente le stock des produits d’un magasin, et l'autre concerne les commandes des clients. Vous souhaitez combiner ces deux flux afin de créer une projection précise du niveau de stock pour chaque produit. Les scénarios sont les suivants :
- Lorsqu'une commande client est passée, elle doit réduire le niveau de stock correspondant. Par conséquent, il est nécessaire que l'arrivée d'une commande déclenche un calcul et une mise à jour de la projection.
- Lorsque le stock des produits dans le magasin est actualisé, il doit également mettre à jour le dernier stock de base de chaque produit, déclenchant ainsi un nouveau calcul et une nouvelle projection.
En d’autre termes, nous avons besoin de faire une double jointure entre le flux des stocks et le flux des commandes et tout cela en temps réel. Comment faire cela dans Kafka Streams ?
Jointure KTable-KTable
Kafka Streams est un outil pour traiter des données en temps réel. Pour effectuer une jointure en temps réel entre deux flux de données (KStream), on peut faire :
- Jointure KStream-KStream : On conserve les deux flux de données KStream et on utilise une fenêtre (windowing) pour associer tous les éléments correspondants dans une période de temps spécifique.
Dans ce cas, on a bien le flux de commandes qui se joint avec celui des stocks et vice-versa, mais seulement pour ceux arrivant dans la même fenêtre. Il faudrait une fenêtre de temps énorme pour récupérer tout les changements, ce qui fait que l’on ne serait plus en temps réel.
- Jointure KStream-KTable : On transforme l'un des flux en une KTable pour garder les changements d'état, puis on associe chaque élément du flux KStream avec chaque élément de la table KTable.
Dans ce cas, les éléments du flux de KStream (stock ou commande) viendrait se joindre avec la KTable, ce qui produit bien une projection. Mais les éléments de la KTable ne se joindrait pas avec ceux de la KStream, ce qui ne produit pas une projection.
- Jointure KTable-KTable : On transforme les deux flux en deux Ktable, ce qui nous permet de garder les changement d’état des deux sources, et nous permet de joindre chaque élément comme en SQL.
Au vu des descriptions, cela ressemble plus à une jointure KTable-KTable qu’il faudrait faire ! Faisons donc cela.
Voici le modèle de données des stocks et des commandes (orders ici) :
case class Stock(
store: String,
product: String,
checkedAt: Instant,
quantity: Double
)
case class Order(
orderId: String,
store: String,
createdAt: Instant,
items: List[OrderItem],
deliverAt: Instant,
status: String
)Et voici un exemple de construction de la topologie dans Kafka Streams :
/* Create the stock KStream from the stock topic.
*/
val stocks: KStream[Key, Stock] =
builder.stream(StockTopic)(
Consumed.`with`(Key.keySerde, Stock.valueSerde)
)
/* Create a KStream for orders the same way.
*/
val orders: KStream[Key, Order] =
builder.stream(OrderTopic)(
Consumed.`with`(Key.keySerde, Order.valueSerde)
)
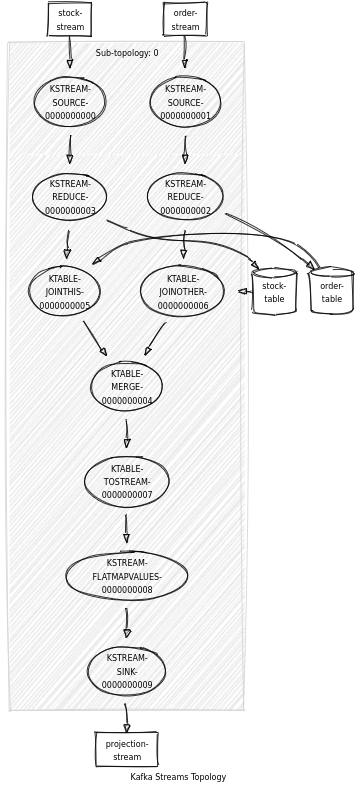
val orderTable: KTable[Key, Order] =
orders
.groupByKey(Grouped.`with`(Key.keySerde, Order.valueSerde))
.reduce((order1, order2) => mergeOrders(order1, order2))(
Materialized.as("order-table")(Key.keySerde, Order.valueSerde)
)
val stockTable: KTable[Key, Stock] =
stocks
.groupByKey(Grouped.`with`(Key.keySerde, Stock.valueSerde))
.reduce((stock1, stock2) => moreRecentOf(stock1, stock2))(
Materialized.as("stock-table")(Key.keySerde, Stock.valueSerde)
)
val projections: KStream[Key, Projection] =
stockTable
.leftJoin(orderTable)((stock, order) =>
project(Option(stock), Option(order))
)
.toStream
.flatMapValues(_.toList)
projections.to(ProjectionTopic)(
Produced.`with`(Key.keySerde, Projection.valueSerde)
)Vous trouverez le code complet ici :
Pouvons nous faire mieux ?
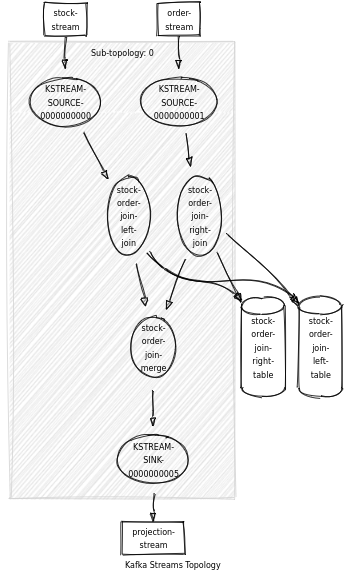
Une autre manière de faire cette jointure est de passer directement par les states stores. Cette méthode consiste à utiliser l’API de bas niveau de Kafka Streams afin de faire une double jointure partielle à l’aide des méthodes .get et .put des state stores. Cela nous permet de ne pas devoir transformer les données de KStream en KTable, et donc de faire une jointure KStream sans fenêtrage qui répond à nos attentes.
Le code se trouve ici avec l’utilisation de la case class ExtraStreamBuilder :
En faisant une visualisation de la topologie pour chaque code, nous voyons bien la simplification (à gauche jointure KTable-KTable, à droite double jointure partielle)
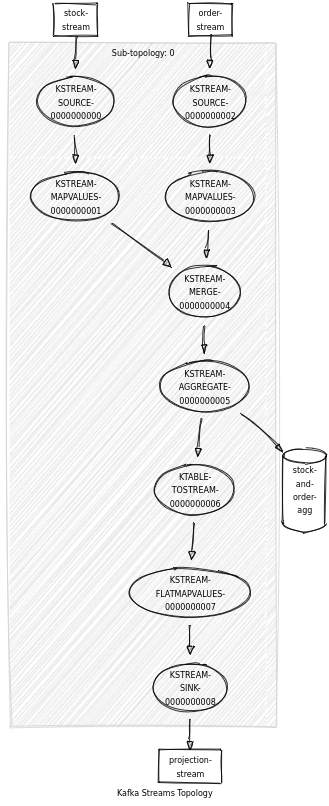
Encore mieux ??
En allant un peu plus loin, pour optimiser cette double jointure on peut aussi… supprimer la notion de jointure des deux flux. Non ce n’est pas un clickbait ! Cette méthode consiste à prendre les deux flux et à les fusionner dans un seul schéma dès le début. Cela semble bizarre dit comme ça, mais voyons un exemple pour mieux comprendre.
Pour rappel nous avons les deux flux de stocks et de commandes :
case class Stock(
product: String,
checkedAt: Instant,
quantity: Double
)
case class Order(
product: String,
quantity: Double
)Nous fusionnons ces deux schémas en un seul en utilisant les mettant en Option tous les deux :
case class StockAndOrder(
stock: Option[Stock],
order: Option[Order]
)Et voilà ! Nous avons un ADT qui représente toutes nos sources (ici il n’y en a que deux mais il pourrait y en avoir d’autres).
Nous transformons ensuite le stream des commandes avec le schéma StockAndOrder :
val orders: KStream[Key, Order] =
builder.stream(OrderTopic)(
Consumed.`with`(Key.keySerde, Order.valueSerde)
)
val finalOrders = orders.mapValues(_.toStockAndOrder)Et pareil pour le stream des stocks :
val stocks: KStream[Key, Stock] =
builder.stream(StockTopic)(
Consumed.`with`(Key.keySerde, Stock.valueSerde)
)
val finalStocks = stocks.mapValues(_.toStockAndOrder)Nous fusionnons les deux streams avec un merge (car ils ont maintenant le même schéma)
val mergedStream = finalOrders.merge(finalStocks)Puis nous aggrégeons le tout dans une KTable. Dans cette étape, nous faisons un groupByKey qui va permettre d’aggréger deux StockAndOrder. Selon qu’on ait l’information de stock ou l’information d’order dedans qui est définie, on peut avec un match décider quelle information va être apportée dans la KTable (current.copy). Enfin en sortie, nous pouvons transformer StockAndOrder en Projection avec un flatMapValues
val projections =
mergedStream
.groupByKey(Grouped.`with`(Key.keySerde, StockAndOrder.valueSerde))
.aggregate(StockAndOrder.empty){
(_, newValue, current) =>
(newValue, current) match {
case (_, StockAndOrder.empty) => newValue
case (StockAndOrder(None, _), _) => current.copy(order = newValue.order)
case (StockAndOrder(_, None), _) => current.copy(stock = newValue.stock)
}
}(
Materialized.as("stock-and-order-agg")(Key.keySerde, StockAndOrder.valueSerde)
)
.toStream
.flatMapValues { v =>
project(v.stock, v.order) match {
case Some(v) => Seq(v)
case None => Seq.empty
}
}Le principal avantage avec cette méthode, c’est que nous évitons du shuffle puisque nous supprimons les jointures. Nous avons également une seule source en entrée avant l’aggrégation, nous pouvons donc remplacer le début de cette topologie plusieurs micro-services sources qui viendraient alimenter un unique topic.