C'est quoi, ça marche comment ?
Un aperçu d’Apache Pulsar
Apache Pulsar est un système distribué open-source dédié à la messagerie et basé sur le modèle “publish-subscribe”. Il a été développé chez Yahoo et mis en production depuis trois ans pour des applications comme Yahoo Mail, Yahoo Finance, Yahoo Sports, Flickr, Sherpa ou encore Gemini Ads. Depuis fin 2016, le projet a été mis en open-source sous la fondation Apache.
Dans cet article, nous allons explorer les différents concepts constituant Pulsar ainsi que son architecture.
Publish-Subscribe (pub-sub) et la triade : producteur, topic et consommateur
Pulsar fait partie des systèmes de messagerie utilisant le modèle du publish-subscribe : la publication et l’abonnement. Ce modèle est composé de trois différents éléments permettant la transmission des messages : les producteurs, les topics et les consommateurs. Les producteurs et les consommateurs, comme leur nom l’indique, sont des applications produisant et consommant des messages. Dans le vide ? Non ! C’est là que le topic intervient. Le topic joue le rôle d’intermédiaire entre les producteurs et les consommateurs et stockent les messages. En résumé, les producteurs publient leur messages dans différents topics et les consommateurs s’abonnent à différents topics pour consommer les messages. Cette indirection permet de découpler les producteurs des consommateurs, ils ne se parlent pas directement.
Topic, namespace, tenant
Le topic est la figure centrale de Pulsar puisque c’est par là que transitent et sont potentiellement stockés tous les messages. Les topics sont comme des stockages structurés pour l’écriture de logs (log-structured storage), où chaque message possède un offset.
Dans Pulsar, les topics ne sont pas indépendants, ni dispersés dans la nature. Un principe que Pulsar prône est d’être multi-tenant (i.e. multi-entité). Pour ce faire, les topics doivent être organisés en tenant et namespace. Pour faire simple, un namespace contient plusieurs topics et un tenant contient plusieurs namespace. Cela permet d’avoir différents niveaux de permissions, réplications, d’expiration de messages et autres, entre les différents namespaces et tenant.
Les topics dans Pulsar peuvent être persistant ou non-persistant. Persistant veut dire ici que les données sont stockées de manière durable dans un disque (ou plusieurs car nous sommes dans le monde distribué).
Pour résumer, les noms des topics sont représentés par une URL de la forme suivante :
{persistent|non-persistent}://tenant/namespace/topic
Subscription mode, multi-topic subscription
Pour s’abonner à un topic, un consommateur ou un groupe de consommateurs peuvent établir un contrat appelé “subscription”. Les “subscription” contiennent des métadonnées et un curseur. C’est ce curseur qui suit l’offset du topic courant pour chaque consommateur.
Il existe trois différents “subscription” dans Pulsar :
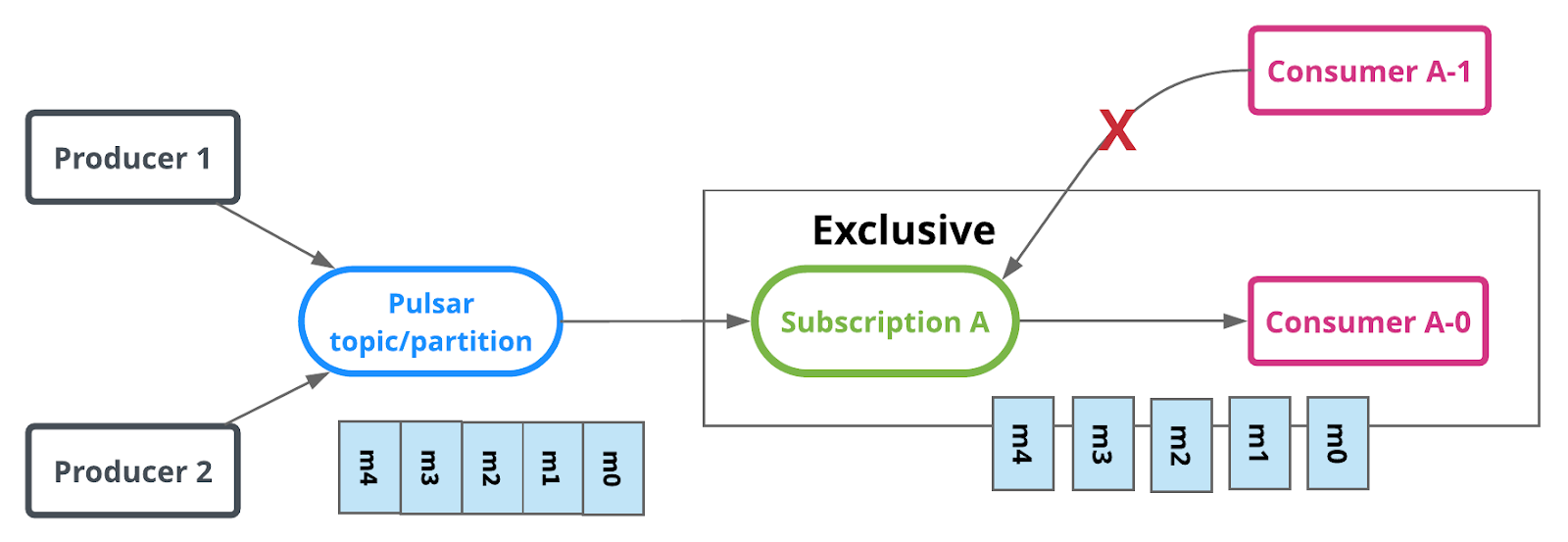
- Exclusive subscription
Ce mode permet à un seul et uniquement consommateur de s’abonner à un topic.
- Shared subscription
Ce mode permet à plusieurs consommateurs de s’abonner à un topic.

- Failover subscription
Ce mode permet de définir plusieurs consommateurs pour un topic. Sauf qu’à la différence du shared subscription, il n’y a qu’un seul consommateur abonné au topic. Les autres sont là au cas où le consommateur abonné se déconnecte (d’une manière ou d’une autre).

Cela permet de choisir la meilleure façon de consommer les données. Si l’ordre des données est importante (chaque donnée dépend des données précédentes), on préférera utiliser soit le mode “exclusive”, soit le mode “failover”. Sinon, on utilisera le mode “shared” où l’ordre des messages n’est pas garanti, mais qui permet de consommer plus rapidement avec plus de consommateurs.
Les consommateurs peuvent également s’abonner à différents topics (à la condition que ceux-ci soient dans le même namespace). Il y a deux façons pour le faire :
- Établir explicitement la liste des topics à lire.
- Définir par regex la liste des topics (ex :
persistent://tenant/namespace/topic-*).
Dans ce cas-là, l’ordre des messages consommés n’est pas garanti (comme pour le shared subscription).
Acknowledgement
Dans Pulsar, il est important pour un serveur de savoir si un consommateur a fini de récupérer un message afin de décider s’il peut le supprimer ou pas. Le consommateur doit donc envoyer un “ack” (acknowledgement) permettant de faire savoir au serveur qu’il a bien reçu le message.
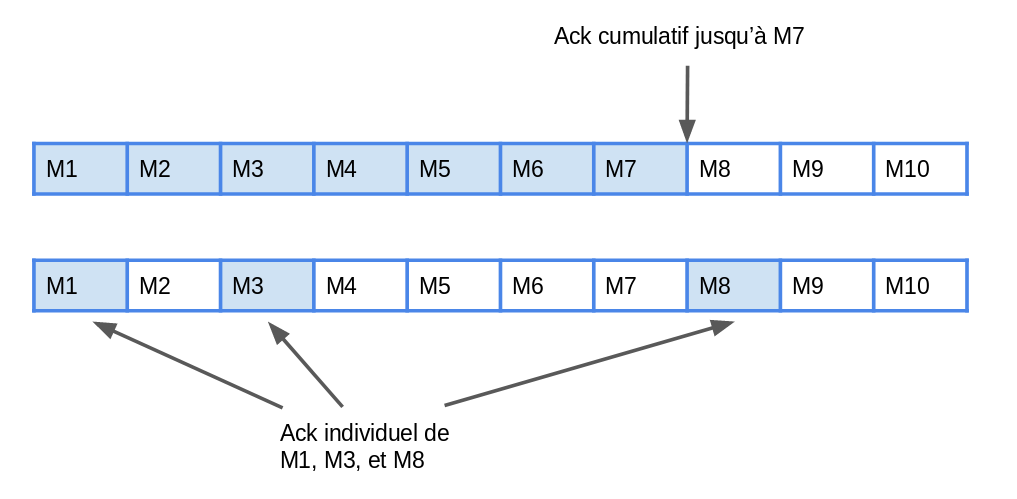
Ce “ack” est géré par les curseurs dans les subscriptions et permet à un même message de ne pas être consommé plusieurs fois. Le ack peut être fait de manière cumulative (tous les messages jusqu’à un certain point sont ack) ou individuel (un par un) :
Il permet également de définir les concepts d’expiration de message et rétention de message.
“Mais ce n'est pas la même chose ?”
Non ! Dans Pulsar par défaut, les messages non-ack ont un visa temporaire dans les serveurs et sont supprimés dès qu’ils sont ack. On peut prolonger ce visa lorsqu’ils sont ack en modifiant la rétention du message. À l’opposé, on peut diminuer le temps de ce visa lorsque les messages sont encore non-ack en modifiant l’expiration du message (appelé aussi TTL = Time To Live). Ces deux concepts permettent deux choses :
- Garder les données pendant un certain temps même s’ils ont été ack (rétention)
- Supprimer les données après un certain temps même s’ils n’ont pas été ack (TTL)
Cela permet également de voir Pulsar comme une queue si les messages ne sont pas gardés après ack, ou comme Apache Kafka où les messages sont persistés un certain temps après leur consommation.
To sync or not to sync
Les producteurs et consommateurs ont la possibilité d’envoyer ou de recevoir les messages de manière synchrone ou asynchrone.
Pour le producteur, un envoi synchrone correspond à une attente de confirmation de réception à chaque envoi de message et, dans le cas échéant, un échec d’envoi du message de la part du producteur. Un envoi asynchrone correspond à l’envoi direct d’un message dans une queue de messages, sans attente de confirmation de la part de Pulsar.
Pour le consommateur, une réception synchrone permet de bloquer l’exécution jusqu’à ce qu’un message arrive. Une réception asynchrone utilise une future value (CompletableFuture en Java par exemple).
Architecture
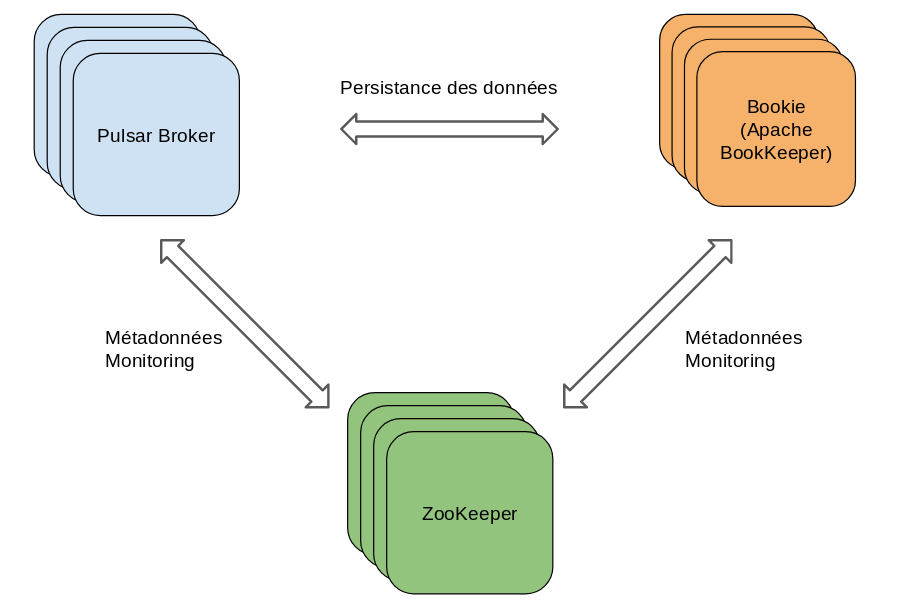
Maintenant que nous avons vu les différents concepts de Pulsar, regardons comment cela marche en vrai. Un cluster Pulsar est composé de trois principaux éléments :
- Des brokers (serveurs) permettant d’acheminer les messages vers les différents consommateurs, communiquer avec la configuration Pulsar pour permettre la coordination de tâches, stocker des messages dans les “bookies” (instances BookKeeper), etc.
- Un cluster BookKeeper (bookies) permettant de persister les messages (c’est comme cela que les topics peuvent être persistants !).
- Un cluster ZooKeeper pour gérer les métadonnées des brokers et bookies et surveiller la santé de ceux-ci.
Divide ut regnes
Cette architecture en cluster permet d’établir les concepts vu précédemment de sorte que tout soit distribué. En effet, chaque topic a la possibilité d’être divisé en partitions (appelés partitioned topics). Ces partitions (représentant un morceau du topic) sont répartis automatiquement dans les différents broker Pulsar de manière la plus équitable possible (eg. s’il y a trois brokers et cinq partitions, deux brokers auront deux partitions chacun et la dernière partition sera affectée au troisième broker).
Avec le mode partitioned topic, les consommateurs et producteurs atteignent ainsi une plus grande capacité de traitement. Attention, cela est différent du mode shared subscription où la consommation d’un topic est partagée entre plusieurs consommateurs !
Conclusion
Pour conclure, Apache Pulsar est un système de messagerie qui se veut multi-fonction et multi-entité. L’architecture de Pulsar permet d’avoir un système de type publish-subscribe qui peut également prendre la fonction d’un système de type queue avec les bons paramètres. La différenciation de niveau pour les topics (tenant, namespace, topic) permet une séparation d’entité.
Pour continuer sur le thème des systèmes de type publish-subscribe, vous pouvez consulter cet article sur notre blog décrivant Apache Kafka, un système similaire à Apache Pulsar avec néanmoins plusieurs différences au niveau de l’architecture et des concepts.
Si vous voulez en savoir plus sur l’architecture d’Apache Pulsar et notamment à propos de la persistance des données avec Apache BookKeeper, je vous invite à consulter l'article de Jack Vanlightly : "Understanding how ApachePulsar works".