Kafka 0.10
- Kafka Streams
- Rack awareness
Kafka 0.11
- Record headers
- Exactly-once semantic
Kafka 1.0
- Améliorations diverses
Kafka 2.0
+ ACLs, sécurité
Introduction
Alors que dans la plupart des systèmes d'information, la donnée est vue comme un élément sujet au cours du temps à de nombreuses modifications et qu'il faut entreposer sous toutes ses formes (en ajoutant en plus des couches de caches pour des raisons de performances et des couches d'audit pour savoir par qui, quand et comment la donnée a été modifiée) et que les inévitables migrations de ces entrepôts sont perçues comme des projets pharaoniques voire insolubles, il y a des solutions qui vous proposent de sortir de ce carcan et de vous offrir une vision en flux, permettant de fournir une plus grande flexibilité dans les systèmes d'information. Avec nombre d'avantages complétant cette vision, Kafka est de ces solutions.
Depuis sa sortie en 2011 au sein de LinkedIn, Kafka est devenu une plateforme hautement recommandée, voire quasiment incontournable, dans le monde de la data. Open Source via le modèle de la fondation Apache (comme Hadoop, Spark ou Cassandra) et fortement soutenu par Confluent (la société fondée par les créateurs de Kafka), Kafka a déjà des adeptes importants comme Netflix, Uber, Twitter ou Goldman Sachs. Et en Europe, il y a Criteo, ING, Natixis, EDF, etc.
Kafka est librement téléchargeable. Mais ce framework est aussi inclue à des distributions Hadoop. Par exemple, Hortonworks le propose dans son offre DataFlow (HDF). Nous pouvons aussi trouver Kafka en tant que service managé auprès des cloud providers. Cette plateforme est ainsi disponible chez Confluent (avec une plateforme dédiée) et AWS.
Ce qui fait la particularité de Kafka, ce qui le différencie des approches alternatives, c'est que Kafka impose une vision distribuée et hautement disponible, tout en proposant une API bas niveau — ainsi, il est facile de rentrer dans les méandres de la plateforme et de son architecture. Pour paraphraser Confluent, il s'agit d'un gage de performance.
Nous allons dans cet article revenir les différentes utilisations de Kafka, puis nous verrons l'architecture de Kafka et observer assez rapidement son écosystème, tout en nous intéressant aux apports.
Quels sont les usages de Kafka ?
Il y a autour de Kafka plusieurs cas d'utilisation possibles. Son principal usage est lié à sa capacité à transférer de la donnée même si son volume est important, avec un haut niveau de fiabilité entre des services répartis. En se basant sur des flux nommés de données découpés en messages, autour desquels des services peuvent envoyer et d'autres services peuvent se mettre en attentes d'un envoie, en proposant de répartir et répliquer ces flux sur plusieurs machines, Kafka facilite la mise en place de systèmes répartis.
En effet, d'un côté, Kafka assure à la fois une transmission asynchrone des données entre les services. Ainsi, lorsque le développeur crée un service, il n'a pas nécessairement besoin de passer par du temps sur ces aspects. D'un autre côté, Kafka offre une haute disponibilité de son service et des données qu'il gère. Cet aspect possible grâce au mécanisme de répartition / réplication.
Il facilite aussi une vision alternative sur la donnée gérée par une entreprise : une vision unifiée dans laquelle nous accordons une importance à la transmission des événements modifiant les données, plus qu'au stockage d'un état mutable. L'état est ainsi reconstruit à partir de ces événements. Cette approche offre plus de flexibilité sur l'organisation d'une application ou d'un système d'information, avec la capacité conserver explicitement l'historique de la donnée ou de réinterpréter les événements pour en extraire d'autres données ou apporter des corrections.
Néanmoins, malgré les facilités offertes par Kafka, il est nécessaire de garder à l'esprit que nous sommes en présence d'un système réparti et que la conception d'un tel système repose sur un découplage des différents services qui le compose. Autre point, Zookeeper est une dépendance sur laquelle Kafka se base pour gérer son fonctionnement. Déployer Kafka revient donc à déployer deux services et Zookeeper n'est nécessairement le plus simple dans cette catégorie. Enfin, il y a bien évidemment des cas où Kafka sera de trop, en particulier si les volumes sont faibles ou les producteurs ou consommateurs autour de la données sont peu nombreux. Dans ces cas, une simple base de données relationnelle peut suffire.
Dans le détail...
Kafka a été créé par LinkedIn afin de faciliter et unifier la communication et la transmission de données dans le cadre de la transition vers une architecture microservices. Kafka apparaît donc comme un MOM (Message Oriented Middleware) dans ce cadre.
Depuis sa version 0.10, Kafka propose une API de traitement de données en flux, appelée Kafka Streams, et une API d'intégration, appelée Kafka Connect. Ces API facilitent la mise en place de chaîne de traitements, notamment dans le cadre de traitements BigData ou sur des architectures microservices.
Kafka peut aussi être utilisé pour agréger les logs provenant de plusieurs applications, par exemple dans le cadre d'une application microservices. Certains frameworks de log permettent de transmettre les logs directement dans Kafka.
De ces premiers cas d'usage, il est possible de constituer assez simplement des fonctionnalités de type analytics, de système de mise à jour de vues, d'éviction de caches...
Kafka est un framework basé sur le concept de commit-log ou journal de commits. Dans le cadre d'une base de données, un commit correspond à l'étape d'"engagement" des opérations impliquées dans une transaction. Il existe des cas d'utilisation où Kafka est adossé à une base de données, afin de récupérer l'ensemble des modifications sur cette base. Ceci est réalisé dans un but de réplication de la donnée et aussi afin de pouvoir reconstruire la base en cas de panne.
En partant de ce cas d'usage, il est possible de transformer Kafka en base de type event source. Dans ce cadre, ce qui est stocké ce n'est pas l'état de la donnée, mais l'ensemble des événements ayant participé à modifier cette donnée. L'état est alors déduit à partir de cet ensemble d'événements. Kafka n'est pas le meilleur outil pour l'event sourcing. Une base comme Event Store sera plus adaptée. Mais, dans la mesure où il est déjà en place, Kafka permet d'explorer ce paradigme.
Architecture et fonctionnement
Kafka est avant tout une plateforme permettant de transférer des messages, aussi appelés des logs, entre différents processus. Il s'apparente en ce sens à d'autres frameworks comme RabbitMQ ou ZeroMQ, ou des solutions Cloud comme PubSub chez Google et Kinesis chez AWS.
Architecture
Il y a deux points de vue avec Kafka : la vue physique qui concerne l'intégration avec les infrastructures d'un cluster et la vue logique qui concerne l'organisation que fait apparaître la plateforme afin de permettre la transmission de messages.
D'un point de vue physique, de base les instances de Kafka sont réparties dans un cluster. Les instances de Kafka, appelées brokers, sont réparties sur plusieurs machines. Elles permettent à la fois de répartir la charge et de répliquer les messages.
D'un point de vue logique, les messages sont transmis sur des topics nommés. Un topic va être constitué de plusieurs partitions, réparties dans les différents brokers. Au niveau d'un topic, des processus vont jouer le rôle de producteur pour ceux qui envoient des messages et d'autres processus vont jouer le rôle de consommateur pour ceux qui attendent la réception de messages.
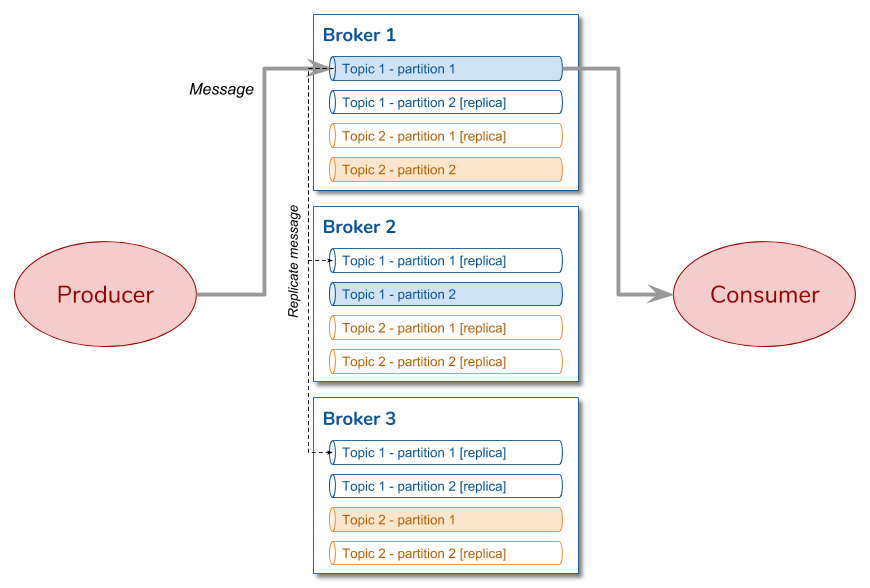
Kafka se base sur Zookeeper pour gérer une partie de son fonctionnement (liste des topics, offset...). Une migration est prévue pour intégrer l'algorithme de consensus Raft afin de rendre Kafka plus indépendant.
Fonctionnement
La connexion à Kafka se fait en créant un producteur ou un consommateur et en passant en paramètre un ensemble de propriétés. Il faut au minimum préciser l'ensemble des brokers qui seront utilisés, ainsi que les outils de sérialisation qui seront utilisés pour la clé et la donnée dans les messages. Les messages apparaissent en effet sous la forme clé-valeur, avec la possibilité d'ajouter une en-tête depuis la version 0.11.
Pour le consommateur, il faut en plus préciser un group ID pour indiquer dans quel groupe se trouve le consommateur. Ce group ID est surtout utilisé lorsque plusieurs consommateurs sont utilisés en parallèle. Si des consommateurs sont dans le même groupe, ils sont en compétition pour consommer les messages. Dans ce cas, si un consommateur récupère un message, les autres consommateurs du groupe auront les message suivants. Si les consommateurs sont dans des groupes séparés, alors ils fonctionnent en parallèle pour consommer les messages. Dans ce cas, si un consommateur d'un groupe récupère un message, les consommateurs des autres groupes pourront aussi récupérer ce même message s'il ne l'ont pas déjà fait.
L'envoi d'un message par un producteur se fait en utilisant la méthode send(). Cette méthode prend en paramètre un ProducerRecord, qui doit préciser au minimum le topic et le contenu du message. Il est possible de spécifier la clé du message, la partition, des en-têtes et un timestamp. Depuis Kafka 0.11, il est possible de regrouper des messages dans des transactions. Dans une transaction, les messages peuvent être destinés à plusieurs partitions d'un même topic et aussi à plusieurs topic. Les transactions sont atomiques et il est possible de les interrompre (comme pour une base de données relationnelle).
Pour qu'un consommateur reçoivent des messages, il faut que celui-ci souscrive à un ou plusieurs topics (il est possible de spécifier ces topics en fournissant une expression régulière). L'attente d'un message se fait avec la méthode poll(), qui retourne un ConsumerRecords représentant l'ensemble des messages récupérés depuis les topics souscrits. Il faut nécessairement indiquer un temps d'attente maximal. Si ce temps est dépassé, poll() retourne une structure vide. Un ConsumerRecords est composé de ConsumerRecord. Dans une telle structure, il est possible de récupérer les informations transmises au niveau du producteur, ainsi que l'offset du message dans une partition donnée.
Fonctionnement d'un topic
Nous avons vu qu'un topic est composé de partitions. Chaque partition est en fait un fichier sur disque. Il est en ajout seulement pour le producteur et en lecture seul pour le consommateur. Chaque message est ajouté à la fin du fichier et se voit attribué un numéro séquentiel appelé offset, indiquant le numéro d'arrivée du message dans la partition.
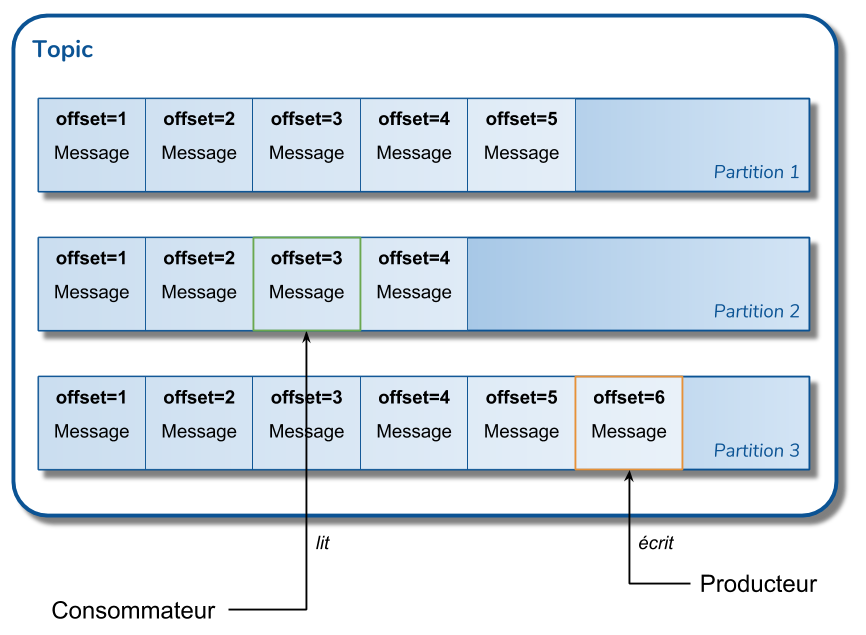
L'ordre des messages est garanti au niveau d'une partition. Par contre, il n'est pas garanti au niveau d'un topic, si celui-ci contient plusieurs partitions.
Pour résumer
La persistance est donc au cœur de la plateforme, car Kafka se base principalement sur de la gestion de fichiers. Sur ce point, les performances de Kafka sont du coup directement dépendante du matériel utilisé, de la gestion de ce matériel par le hardware et aussi la gestion de ce matériel par l'OS. Il faut aussi savoir que le moindre message transmis sur le réseau est d'abord enregistré sur disque.
La tolérance à la panne est assurée à travers la réplication des partitions entre les brokers. Si une machine tombe en panne, les opérations sont reprises au niveau d'un réplicat, qui devient lead.
Écosystème de Kafka
Il existe tout un écosystème autour de Kafka afin de le spécialiser autour de différents usages (gestion de flux de données, connexion à des services externes, gestion des schémas...). Une partie de cet écosystème est fourni avec la plateforme Confluent. Nous n'aborderons pas cette plateforme ici et nous verrons juste Kafka Streams et Kafka Connect disponibles librement.
Kafka Streams
Kafka Streams est un framework qui permet de faciliter le stream processing. Nous sont ainsi fourni à travers une API des transformations, voire des outils pour remodeler les données gérées par Kafka entre différents topics. Plus précisément en terme d'opération, il est possible de modifier les logs un à un (map), d'ajouter des logs (flatmap), de les filtrer, de regrouper des logs selon une clé donnée (group-by) et même de fusionner des topics (join).
Kafka Connect
Kafka Connect est un framework permettant de transférer des données en flux entre différents systèmes, en se basant sur Kafka. En terme de système, il peut s'agir de SGBDR, de base NoSQL, de récupération de logs, de stockage sur le Cloud, etc.
Confluent fourni un hub contenant différents connecteurs : https://www.confluent.io/hub/.
À propos...
Ensemble Kafka Streams, Kafka Connect et Kafka couvrent ainsi les besoins couverts par des frameworks comme Apache Camel ou Akka Stream et permettent de remplacer les ESB par une plateforme de stream processing et/ou orientée événements... En tout cas, là où les ESB représentent une approche trop lourde et peu flexible, c'est-à-dire dès qu'il s'agit juste de mettre à disposition des flux de données caractérisés. L'avantage qu'apportera Kafka, dès lors que son cas d'usage est respecté, sera de fournir en plus de la performance et de la haute disponibilité.
Conclusion
Kafka et son écosystème présentent ainsi de nombreux avantages pour mettre en place non seulement un bus de messages, mais aussi un outil de transport et transformation de données, en particulier avec des données en flux. Tout ceci est réalisé en bénéficiant des optimisations sous-jacentes à Kafka et aussi d'un système de persistance, de réplication et de partitionnement assurant une haute disponibilité de la plateforme.
Toutes ces particularités font de Kafka un outil à part entière, qui est certes générique, mais qui est capable de supplanter bon nombre d'outils spécialisés autour de la donnée, tant Kafka en plus d'être performant, apporte beaucoup de flexibilité.
Draft 0.1
Kafka est sorti récemment en version 2.1. Cette version inclue un certains nombres de correctifs par rapport à la version 2.0, mais aussi l'intégration de Java 11 et la possibilité de un nouvel algorithme de compression développé par Facebook et plus rapide que GZip pour un taux de compression équivalent : ZStandard.
Cette article est l'occasion de revenir sur les dernières évolutions de Kafka par rapport aux versions encore assez utilisés dans les systèmes d'information actuels : nous allons pour cela partir de Kafka 0.10.
Le versioning dans Kafka
Les numéros de version de Kafka ne suivent pas exactement un schéma classique. Par exemple, les changements entre la 0.10 et la 0.11 sont plus important que les changements apparaissant entre la 0.11 et la 1.0, sachant que la 1.0 est plus une version de stabilisation. Autre exemple, les nouveautés la 2.1 crée un changement qui ne permet pas de revenir aux versions précédentes.
Kafka 0.10
Jusqu'à la version 0.10, Kafka était déjà connu comme un framework de messaging distribué.
Avec la version 0.10, Kafka devient aussi un framework de streaming.
Kafka 0.11
Header
Dans un objectif de s'aligner avec la plupart des protocoles réseaux, comme HTTP ou TCP, ainsi que les systèmes de message, comme JMS ou QPID, la version 0.11 de Kafka permet d'ajouter un en-tête à chaque message. Un message est donc depuis cette version défini :
- par un corps, composé d'une clé et d'une valeur ;
- par une en-tête, qui est un ensemble clé-valeur.
L'en-tête permet d'ajouter des méta-données aux messages dans différents objectifs, comme le routage automatique des messages entre différents cluster, l'intégration d'informations d'audit comme l'ID client, l'ID cluster où a été produit le message, etc. ou enfin, la mise en place de métriques.
Une en-tête est représentée par l'interface Header. Dans celle-ci, la clé est sous forme d'une chaîne de caractères (String) au format UTF-8 et le contenu sous forme de tableau d'octet (byte[]). Ce qui permet d'y mettre toute sorte de données sérialisées.
Les Header sont rassemblés dans une structure mutable appelé Headers. Il s'agit d'une interface dérivé de Iterable<Header>. C'est cette structure qui rattachée aux Record depuis Kafka 0.11.
Dans Headers, les méthodes les plus intéressantes sont :
add(String key, byte[] value)pour ajouter une métadonnée ;Iterable<Header> headers(String key)pour retourner toutes les en-têtes dont la clé estkey.
Il y a aussi Header lastHeader(String key), qui retourne la "dernière" métadonnée de clé key. Mais il ne semble pas avoir d'explication sur ce qui est entendu par "dernière". Dans l'implémentation actuelle, un java.util.ArrayList est utilisé pour stocker les en-têtes. Dernière dans cette implémentation signifie l'élément avec le plus grand indice. La recherche se fait donc en O(n) en partant du dernier élément.
Exactly once
Il existe typiquement trois sémantiques de livraison de message dans un système répartie :
- At-least-once : le système garanti qu'un message sera transmis et qu'il apparaît au moins une fois au niveau d'un consommateur. Ce qui veut dire qu'un message produit pourra être consommé. Ce qui veut aussi dire qu'un message peut être dupliqué.
- At-most-once : le système garanti qu'un message ne sera pas dupliqué. Mais il peut ne pas transmettre le message.
- Exactly-once : le système garanti qu'un message produit sera transmis et fourni en un seul exemplaire au consommateur.

 https://www.youtube.com/watch?time_continue=3&v=lIGFH9TkL2w
https://www.youtube.com/watch?time_continue=3&v=lIGFH9TkL2wLa GetSet parisienne qui découvre Kafka

 https://lescastcodeurs.com/2018/07/30/lcc-193-interview-apache-kafka-avec-florent-ramiere/
https://lescastcodeurs.com/2018/07/30/lcc-193-interview-apache-kafka-avec-florent-ramiere/