Imaginez : vous constituez une topologie pour votre service Kafka Streams. Pour éviter de surcharger un consommateur (parce qu'il est un peu lent) ou de surcharger Kafka (parce que son cluster n'a pas la dimension qui convient), sachant que vous avez des messages qui se ressemblent d'un point de vue métier, vous ne souhaitez émettre des messages en sortie que lorsqu'il y a une véritable modification dans les données.
Pour cela, d'un point de vue code, on pourrait bénéficier d'une méthode withEmitOnChange.
val builder = new StreamsBuilder()
builder.stream(inputStream)
.withEmitOnChange
.to(outputStream)Cette fonctionnalité a été imaginée dans Kafka Streams et est référencée dans le document KIP-557: Add emit on change support for Kafka Streams. La solution proposée se base par contre sur une comparaison binaire des données sérialisées pour détecter les modifications.
La fonctionnalité a été livrée dans la version 2.6 de Kafka Streams... Puis a été retirée, parce que des pertes de données ont été constatées. Le Confluence du projet Kafka sur la partie Adopted de la page Kafka Streams indique :
KIP-557: Add emit on change support for Kafka Streams (partially implemented in v2.6 reverted again in 2.8.0, 2.7.1, and 2.6.2 due to potential data loss)
Mais, commençons avec un exemple.
Gestion de stock magasin
Je gère un magasin et dans ce magasin, je gère le stock des produits que je vends sur mon site e-commerce.
Je peux représenter mon stock produit sous la forme d'une case class.
case class ProductKey(storeId: String, id: String)
case class Stock(productId: ProductKey, quantity: Double)J'ai besoin d'un endpoint qui m'indique si un produit est disponible ou non. Voici la représentation de l'information.
case class ProductAvailability(productId: ProductKey, isAvailable: Boolean)Ici, le champ isAvailable est true que lorsque le stock strictement positif.
Nous avons donc là un flux de type KStream[ProductKey, ProductAvailability], en supposant que la structure ProductKey sert ici de clé dans le flux.
Donc, un nouveau produit avec un stock à 10.0 donnera une disponibilité à true et j'ai message qui est créé et qui est envoyé en direction de mon endpoint. Si le stock de ce produit passe à 5.0, la disponibilité reste à true, mais je produis néanmoins un nouveau message pour le endpoint. Si le stock passe à 0.0, alors la disponibilité passe à false et je produis encore une fois un nouveau message. Ici, seule le deuxième message n'est pas utile.
Ce que nous devrions avoir, c'est ce diagramme :
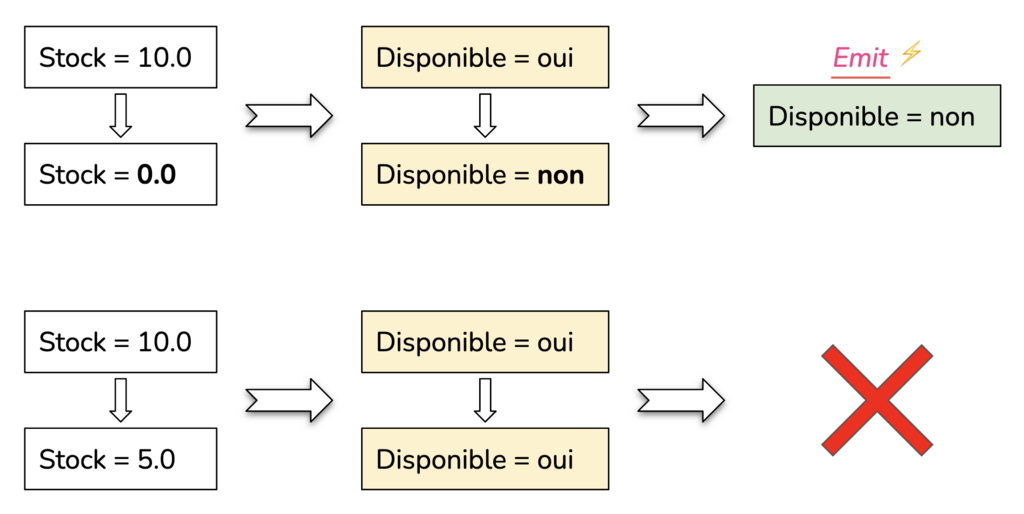
Le but est de n'émettre un message que lorsque la disponibilité passe de oui à non ou de non à oui.
Peut-on contourner l'absence de sémantique emit-on-change ?
Kafka Streams propose deux stratégies d'émission de message :
- emit-on-update
- emit-on-window-close
emit-on-update est une stratégie qui va se traduire par une émission de message pour tout message reçu. On a donc une relation 1..1 entre les données entrantes et les données sortantes.
emit-on-window-close est une stratégie qui consiste à rassembler un ensemble de messages sur des fenêtres de temps et de les agréger pour produire un message en sortie. On a ici une relation *..1 entre les données entrantes et les données sortantes.
La stratégie emit-on-window-close pourrait être utilisée pour mettre en place une stratégie se rapprochant (mais de loin) de la stratégie emit-on-change, en émettant seulement le dernier message de chaque fenêtre (pour des fenêtres fixes), si la véritable problématique provient d'un consommateur trop lent. Il faudra alors trouver une taille de fenêtre adéquate permettant de ne pas trop envoyer de message et en même temps ne pas perdre trop d'information.
Mais peut-on faire mieux ?
L'idée de base de la stratégie emit-on-change est de n'émettre un message que si on observe une modification dans les données en entrée.
Puisque la stratégie emit-on-window-close ne permet pas vraiment d'approcher de la stratégie emit-on-change, nous allons partir de la stratégie emit-on-update.
Nous aurons aussi besoin d'un outil de comparaison permettant de détecter un changement dans la donnée. Il nous faut aussi un stockage pour conserver la dernière version de la donnée, qui servira comme base pour la comparaison avec la donnée arrivant en entrée.
Pour créer notre stockage, nous allons pouvoir nous baser sur un KTable qui sera créé à partir d'un KStream fournit en entrée. Pour cela, nous allons nous baser sur .groupByKey, puis nous avons le choix entre reduce et aggregate. Cependant, reduce ne permet pas de faire la distinction entre ce qui provient du stream entrant et les données qui proviennent du stockage dans la fonction qu'on lui passe en paramètre. Ce qui n'est pas le cas de l'opération aggregate. Nous allons nous baser sur cette opération pour générer un KTable.
À chaque message qui arrive au niveau d'aggregate, un message en sort, du fait de la sémantique emit-on-update. Pour changer de sémantique, nous allons utiliser un filtrage qui permettra d'avoir une sémantique emit-on-change. Mais pour ça, nous devons ajouter une information, un flag qui indiquera si le message doit être émis ou non.
OK, on va revenir à notre exemple de stock disponible, pour pouvoir mieux concevoir tout ça.
Emit-on-change sans emit-on-change
Si nous gardons notre structure ProductAvailability tel que, il n'y a rien qui permettra au filtre de déterminer s'il faut émettre ou non le message. Pour cela il faudrait ajouter un flag qui sera positionné au sein de l'opération aggregate, qui représente le seul endroit dans la topologie, où il est possible de constater une variation de valeur.
case class ProductAvailabilityState(
state: ProductAvailability,
shouldEmit: Boolean
)Nous avons besoin ici d'une valeur empty, car aggregate a besoin d'une valeur initiale.
Les règles prises en compte par la fonction passé en paramètre d'aggregate sont :
val changeLogic:(ProductAvailability, ProductAvailabilityState) => ProductAvailabilityState = {
case (availability, null) =>
ProductAvailabilityState(availability, true)
case (availability, ProductAvailabilityState(storedValue, _))
if availability == storedValue => // <-- the comparison is here
ProductAvailabilityState(availability, false)
case (availability, ProductAvailabilityState(_, _)) =>
ProductAvailabilityState(availability, true)
}
Ici, pour la comparaison, on utilise l'égalité de Scala (comparaison récursive champ par champ).
En sorti d'aggregate, nous avons une KTable[ProductKey, ProductAvailabilityState] que nous pouvons passer au filtre. Ce filtre va simplement vérifier que le flag shouldEmit de notre structure est à true. Après quoi, avec un mapValues, on récupère le champ state. Ce qui nous donne en sortie un flux de type KStream[ProductKey, ProductAvailability] avec une sémantique emit-on-change.
Voici le code correspondant pour la topologie.
availabilityStream
.groupByKey
.aggregate(null: ProductAvailabilityState) {
case (availability, null) =>
ProductAvailabilityState(availability, true)
case (availability, ProductAvailabilityState(storedValue, _))
if availability == storedValue =>
ProductAvailabilityState(availability, false)
case (availability, ProductAvailabilityState(_, _)) =>
ProductAvailabilityState(availability, true)
}
.filter(_.shouldEmit) // apply emit-on-change semantic
.mapValues(_.state.get) // due to filter we are sure to have an instance of SomeCe qui forme la topologie suivante :
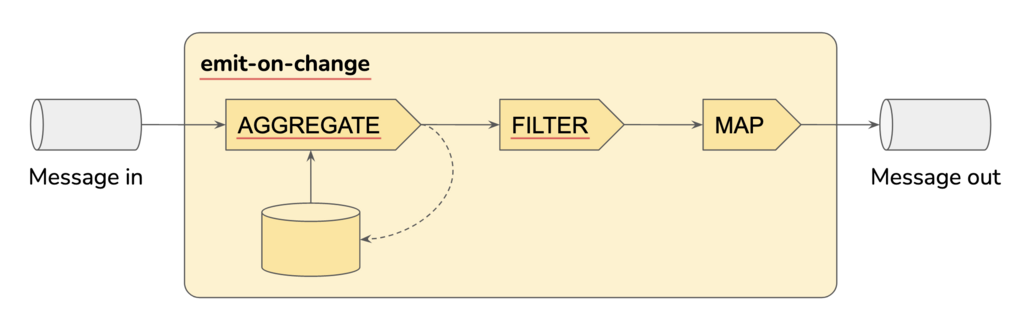
Cette topologie met en œuvre le workflow ci-dessous.
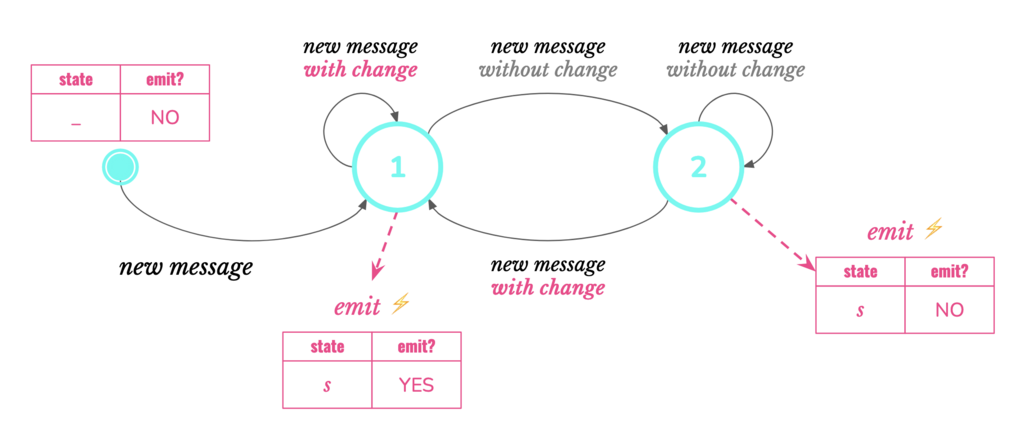
Généralisons
Il est possible de généraliser ce que nous venons de voir à n'importe quel type d'entité utilisée dans vos topologies Kafka Streams.
case class State[A: Equiv](data: A, shouldEmit: Boolean) {
def changeBasedOn(newData: A): State[A] =
State(newData, shouldEmit = !Equiv[A].equiv(data, newData))
}La contrainte Equiv (provenant du package scala.math), implique d'apporter pour le type A un prédicat permettant de vérifier l'équivalence entre deux éléments du type A.
On peut aussi ajouter aux KStream une opération indiquant explicitement que vous passez en sémantique emit-on-change. Il faudra néanmoins fournir une serde pour les entités de type State[A]. Pour on peut utiliser les méthodes d'extension de Scala.
implicit class KStreamEmitOnChange[K, V: Equiv](ks: KStream[K, V]) {
def withEmitOnChange(implicit
keySerde: Serde[K],
serde: Serde[V],
stateSerde: Serde[State[V]]): KStream[K, V] =
ks
.groupByKey(Grouped.`with`(keySerde, serde))
.aggregate(null: State[V]) {
case (_, data, null) => State(data, shouldEmit = true)
case (_, data, state) => state.changeBasedOn(data)
}(
Materialized.`with`(keySerde, stateSerde)
)
.toStream
.filter { case (_, state) => state.shouldEmit }
.mapValues(_.data.get)
}Ce qui dans notre exemple donnerait
implicit val stateSerde: Serde[ProductAvailability] = ???
val builder = new StreamsBuilder()
builder.stream(inputStream)
.withEmitOnChange
.to(outputStream)Parlons performance et volume
La sémantique emit-on-change présentée ici implique de stocker des données dans un state store local au service Kafka Streams exécuté. Ce volume est relatif à la taille de la structure gérée (dans notre exemple, il s'agit de ProductAvailability) à laquelle il faut ajouter la taille utilisée pour le flag (selon le format de sérialisation, c'est soit une chaîne de caractères de taille 4 (true) ou 5 (false), soit un entier sur un octet (8 bit), soit un bit). Cette valeur est à multiplier par le nombre de clé possible.
Si nous reprenons notre exemple avec un format de sérialisation Avro (sans ajout d'en-tête), en supposant que les produits et les magasins sont encodés sur 5 caractères, nous avons donc 13 octets par instance de ProductAvailability (productId et storeId font 2 * (5 octets + 1 octet pour la taille) et le flag fait 1 octet). Si nous avons 5 magasins et 1000 produits par magasin, il faudra prévoir un espace de 65 Ko juste pour la partie data, sachant, qu'il faut ajouter l'ensemble des métadonnées gérées par la couche de persistance RocksDB et plus si vous faites de la réplication.
A priori, dans notre code, nous n'introduisons pas de changement de clé. Il n'y aura pas d'échange de données si vous multipliez les instances de votre service Kafka Streams. Donc la solution devrait scaler. L'exception à cette règle est lorsque withEmitOnChange est précédée d'une opération lazy dans laquelle un changement de clé effectué, ce que permet par exemple .map. Dans ce cas, l'opération .groupByKey va exécuter un re-partitionnement des données. J'écris cependant au conditionnel ici, car je me fis à la documentation Kafka Streams et à l'expérience que j'ai sur les opérations Kafka Streams que j'utilise dans le code. Mais je n'ai actuellement pas de retour suffisamment parlant pour la solution emit-on-change présentée dans cet article.
Conclusion
Nous avons vu dans cet article que la sémantique emit-on-change apporte un moyen de ne pas surcharger Kafka dans de consommateur trop lent ou d'un cluster sous-dimensionné. Il y a une volonté chez les contributeurs Kafka Streams de mettre en place une sémantique emit-on-change, mais cette fonctionnalité rencontre des problèmes de perte de données et est donc retirée.
Nous proposons ainsi une solution intégrant une sémantique emit-on-change qui se base sur les opérations du DSL Kafka Streams. Cette solution est assez simple et n'entraverait pas la scalabilité de l'application.
Il est intéressant de voir qu'avec Kafka Streams il est possible d'ajouter des fonctionnalités au framework en se basant sur son propre DSL. Il est ainsi possible d'imaginer et de cataloguer des patterns de topologie pour faciliter la mise en place sémantiques qui ne sont pas directement couverts par Kafka Streams.
Une proposition alternative est présentée dans cette réponse dans Stack Overflow.