Introduction
Java 16 viens d'être annoncé par Oracle avec un certain nombre de nouveautés intéressantes à voir en détail ici. L'une d'entre elles est la possibilité d'écrire des opérations qui utilisent la pleine puissance des processeurs vectoriels.
On va regarder ensemble rapidement ce qu'il en est et comment utiliser cette API.
Intérêt et cas d'usage
Quand on parle de vectorisation, on parle effectivement de parallélisme, mais pas n'importe lequel. En effet, on pourrait paralléliser un calcul sur plusieurs machines. On parlerait alors d'une architecture en cluster. On pourrait paralléliser un calcul sur plusieurs cœurs d'un même processeur. On parlerait alors de parallélisation inter-coeur.
Dans notre cas, on va chercher à effectuer une parallélisation intra-coeur, c'est-à-dire qu'on va paralléliser un calcul au sein d'un seul cœur à l'aide d'instructions particulières.
On est alors en mesure de se poser la question suivante : "Pourquoi diable voudrait-on s'infliger ça" ?
Les unités de calcul vectoriel sont très présentes dans les GPU, mais on en trouve aussi dans la plupart des processeurs grand public. Avant ça, son usage était réservé aux supercalculateurs (ie. la grande époque des Cray).
L’intérêt du calcul vectoriel est qu'il permet de réduire le nombre de chargements d'instructions. En effet, avec une approche traditionnelle, l'augmentation du nombre de cycles par instruction accélère l'horloge du CPU. Utiliser une approche vectorielle garantie des performances intéressantes comme nous le verrons plus tard dans cet article.
L'optimisation vectorielle permet alors aux processeurs de consommer moins d’électricité et par effet, de prendre plus soin de la planète💡🌎.
Cas d'usage
Typiquement, on peut utiliser la vectorisation pour toutes les opérations faites sur un tableau d’élément.
Prenons l'exemple du calcul de la distance euclidienne entre deux points.
On pourrait modéliser ce problème sous forme de calcul vectoriel comme suit :
Pensons deux vecteurs A et B avec :
| lane 0 | lane 1 | lane 2 | nbr opérations |
|---|---|---|---|
| reduce lanes (ADD) | |||
On remarque que si le nombre de dimensions de notre vecteur augmente - dans une certaine mesure - le nombre d'operations de notre calcul ne change pas.
Prérequis
IDE
Pour pouvoir utiliser un IDE avec Java 16, il vous faudra certainement le mettre à jour :
- IntelliJ:
Il vous faudra une version supérieure ou égale à 2021.1.1
- Eclipse:
Il vous faudra une version supérieure ou égale à 4.20M1
Installer Java 16
Le JDK 16 est disponible sur le site officiel d'oracle vous pouvez le trouver ici
- Distributions linux :
sudo dnf install java-latest-openjdk.x86_64- OSX :
Installation manuelle :
# extract your JDK here
cd /Library/Java/JavaVirtualMachines/
# Change your JAVA_HOME to /Library/Java/JavaVirtualMachines/jdk-16.jdk/Contents/Home- Si vous n'utilisez pas déjà Jenv :
# installez jenv : https://www.jenv.be/
jenv add /System/Library/Java/JavaVirtualMachines/jdk-16.jdk/Contents/Home
jenv global 16Configuration d'IntelliJ
- Pour les flemmards :
Je vous ai préparé un projet maven out of the box à lancer dans votre IDE ici
Au passage voici un petit tips de productivité : vous pouvez lancer vos projets dans IntelliJ directement depuis le terminal en ajoutant un petit alias a votre .zshrc comme ceci
# open current dir in intelliJ
alias intellijize="open -na 'IntelliJ IDEA CE.app' --args './'"- Config manuelle
- pom.xml:
- dependencies :
<dependencies> <!--Unit testing--> <dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter-api</artifactId> <version>5.7.1</version> <scope>test</scope> </dependency> <dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter-params</artifactId> <version>5.7.1</version> <scope>test</scope> </dependency> <dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter-engine</artifactId> <version>5.7.1</version> <scope>test</scope> </dependency> <!--Benchmarking tools for perf review--> <dependency> <groupId>org.openjdk.jmh</groupId> <artifactId>jmh-core</artifactId> <version>1.28</version> </dependency> <dependency> <groupId>org.openjdk.jmh</groupId> <artifactId>jmh-generator-annprocess</artifactId> <version>1.28</version> <scope>provided</scope> </dependency> </dependencies>- Build:
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.1</version> <configuration> <release>16</release> <compilerArgs> <compilerArg>--add-modules</compilerArg> <compilerArg>jdk.incubator.vector</compilerArg> </compilerArgs> <annotationProcessorPaths> <path> <groupId>org.openjdk.jmh</groupId> <artifactId>jmh-generator-annprocess</artifactId> <version>1.27</version> </path> </annotationProcessorPaths> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <version>3.0.0-M5</version> <configuration> <argLine>--add-modules jdk.incubator.vector</argLine> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.2.4</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <finalName>benchmarks</finalName> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>org.openjdk.jmh.Main</mainClass> </transformer> </transformers> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>**/module-info.class</exclude> <exclude>META-INF/MANIFEST.MF</exclude> </excludes> </filter> </filters> </configuration> </execution> </executions> </plugin> </plugins> </build> - config intellij:
- pom.xml:
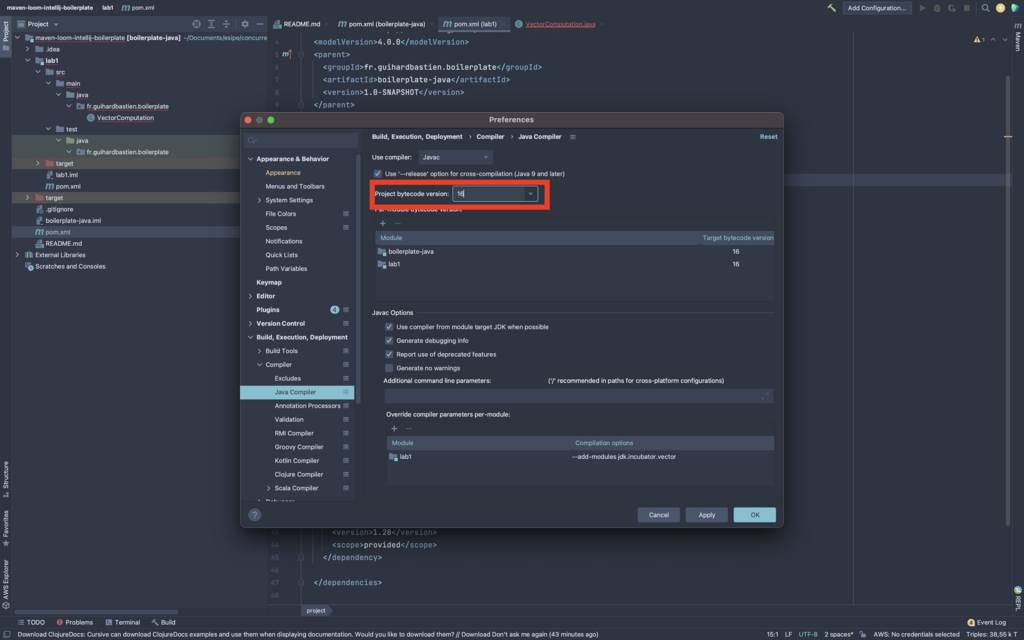
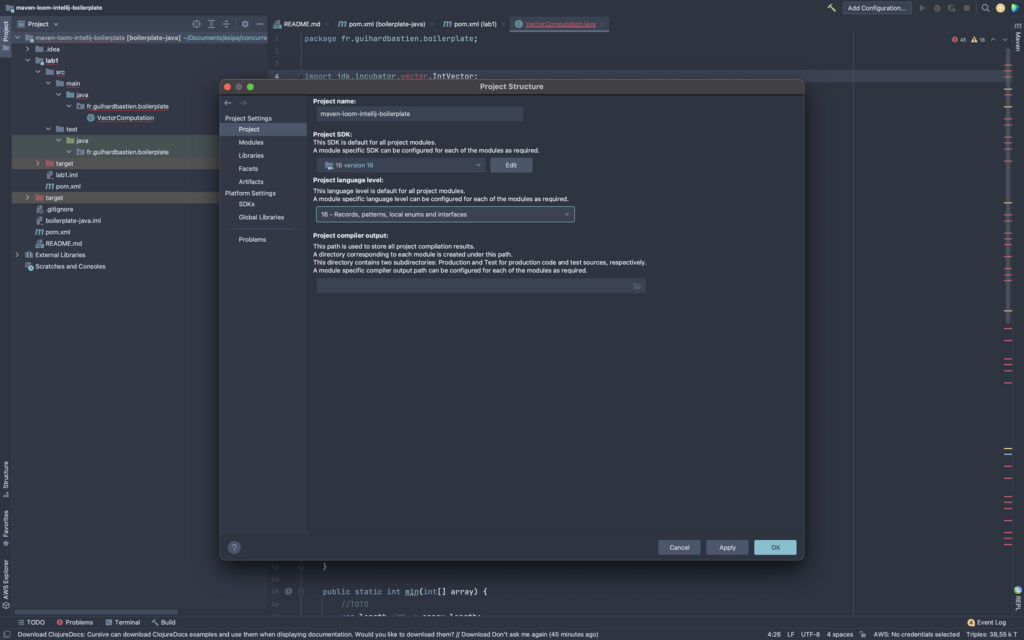
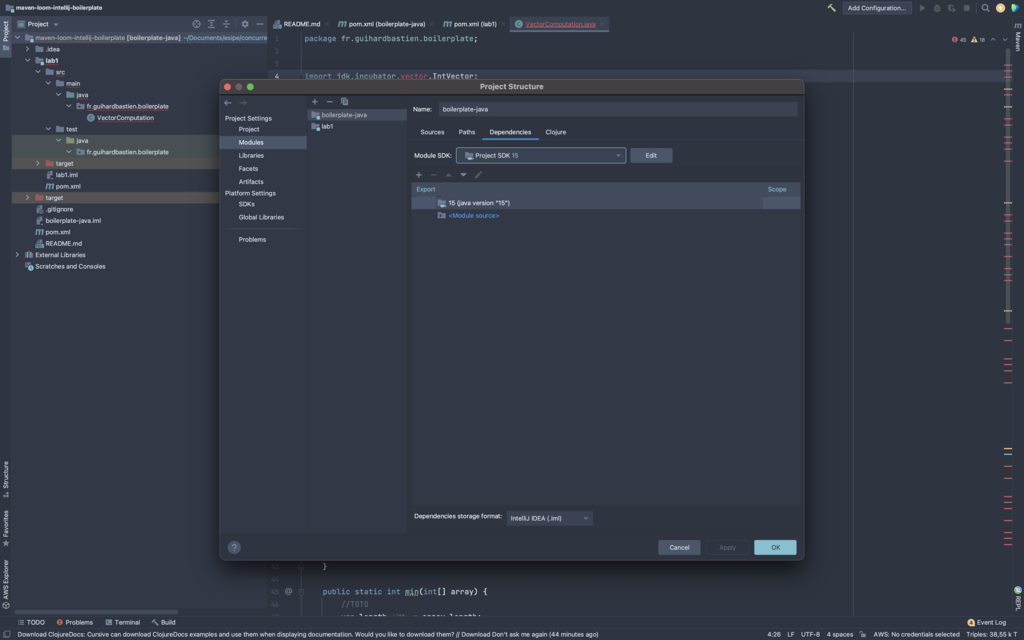
Vérifiez que les dépendences de Modules sont bien en java 16
Un coup d’œil aux CPU "modernes"
L'apparition d'instructions SIMD (lire : Single instruction, Multiple Data) sur les processeurs grand public date des années 90 avec l’extension MMX sur Intel Pentium. On parle plus généralement de processeurs vectoriels.
La page Wikipédia des processeurs vectoriels est très exhaustive. Je vous suggère de la consulter. Pour aller plus loin vous pouvez aussi consulter ce lien et celui ci
- Registres & Lanes
Les registres vectorisés ont une taille supérieur aux registres normaux. Sur les CPU Intel on trouve des registres spécialisés (xmm0, ymm0, zmm0.. cf : https://fr.wikipedia.org/wiki/Advanced_Vector_Extensions) qui effectuent une même opération sur plusieurs lanes
Une opération SIMD indique l'opération, la taille d'une lane et la taille des registres.
Pour l'exemple précédent on a : PADDW xmm0, xmm2, xmm3
avec
- Préfixe
P pour 128 bits
VEX VP pour 256 bits
EVEX VP pour 512 bits
- Opération
ADD pour l’opération
- Taille d’une ligne
B (byte) = 8 bits
W (word) = 32bits
D (double) = 64bits
Q (quad) = 128bits
Les éléments principaux de l'API
Pour lancer une classe avec les bons modules :
java --add-modules jdk.incubator.vector fr.guihardbastien.boilerplate.MainPremiers pas
Pour étudier les éléments important de l'API prenons des exemples simple:
package com.univalence.boilerplate;
import jdk.incubator.vector.IntVector;
import jdk.incubator.vector.VectorSpecies;
public class Main {
public static void main(String[] args) {
VectorSpecies<Integer> species = IntVector.SPECIES_PREFERRED;
IntVector v1 = IntVector.broadcast(species, 20);
IntVector v2 = IntVector.broadcast(species, 22);
IntVector v3 = v1.add(v2);
for (var i = 0; i < v3.length(); i++) {
System.out.println(v3.lane(i));
}
}
}VectorSpecies
Un VectorSpecies indique un type (en l’occurrence Integer) et une shape (taille en bits).
On peut faire référence à IntVector.SPECIES_[64|128|256|512] pour obtenir la shape.
Ici on fait référence a SPECIES_PREFERRED pour - d'après la doc - :
IntVector v1 = IntVector.broadcast(species, 20);
C'est ici qu'on "rempli" nos lanes décrites par le VectorSpecies avec la valeur 20.
Opération
On effectue une addition des deux registres vectorisés : IntVector v3 = v1.add(v2);
Sortie
Sur ma machine on peut voir la sortie suivante :
WARNING: Using incubator modules: jdk.incubator.vector
42
42
42
42
42
42
42
42Les huit affichages nous indiquent que mes registres vectorisés mesurent 256 bits (on additionne 8 int encodés sur 32 bits simultanément)
Deuxième exemple
public class Main {
public static void main(String[] args) {
VectorSpecies<Integer> species = IntVector.SPECIES_PREFERRED;
var arr = new int[]{0, 1, 2, 3, 4, 5, 6, 7};
var b = new int[8];
IntVector vectorizedArray = IntVector.fromArray(species, arr, 0);
IntVector conditionVector = IntVector.broadcast(species, 6);
IntVector addTermVector = IntVector.broadcast(species, 10);
VectorMask<Integer> mask = vectorizedArray.lt(conditionVector); // lt -> lower than
// on ajoute 10 respectivement au mask
IntVector vb = vectorizedArray.add(addTermVector, mask);
vb.intoArray(b, 0);
System.out.println(Arrays.toString(b));
}
}
/* output
WARNING: Using incubator modules: jdk.incubator.vector
[10, 11, 12, 13, 14, 15, 6, 7]
*/Concrètement ici, on effectue une condition relative a un vecteur en créant un masque. En gros, on fait un if vectorisé. Dans notre exemple le masque ressemble à ça : TTTTTTFF.
Pour toutes les lanes qui sont true sur le masque, on leur ajoute 10.
Post-loop & Mask
Pour l'exemple suivant, l'idée est de manipuler un array de manière vectorisée et du finir avec un reduce directement sur les vecteurs.
L'explication du code est faite directement en commentaire.
private static final VectorSpecies<Integer> SPECIES = IntVector.SPECIES_PREFERRED;
public static int sum(int[] array) {
var length = array.length;
// loopBound permet de savoir jusqu'ou on peut vectoriser l'array
// On se servira plus tard d'une "post-loop" pour finir le travail
var loopBound = length - length % SPECIES.length();
// la methode .zero est equivalente à
// IntVector.broadcast(species, 0);
var v0 = IntVector.zero(SPECIES);
var i = 0;
for (; i < loopBound; i += SPECIES.length()) {
// chunk vector of array
var v = IntVector.fromArray(SPECIES, array, i);
// on additionne le contenu des lanes entre eux
v0 = v0.add(v);
}
// ici on on additionne les lanes entres elles
int sum = v0.reduceLanes(VectorOperators.ADD);
// La post-loop qui nous permet de finir le traitement complet de l'array
for (; i < length; i++) {
sum += array[i];
}
return sum;
}Voici un équivalent avec un masque :
public static int sumMask(int[] array) {
var length = array.length;
var loopBound = length - length % SPECIES.length();
var v0 = IntVector.zero(SPECIES);
var i = 0;
for (; i < loopBound; i += SPECIES.length()) {
var v = IntVector.fromArray(SPECIES, array, i);
v0 = v0.add(v);
}
int sum = v0.reduceLanes(VectorOperators.ADD);
var mask = SPECIES.indexInRange(i, length);
var vMask = IntVector.fromArray(SPECIES, array, i, mask);
int sumMask = vMask.reduceLanes(VectorOperators.ADD);
return sum + sumMask;
}Test avec benchmark
Classe VectorComputation
import jdk.incubator.vector.IntVector;
import jdk.incubator.vector.VectorOperators;
import jdk.incubator.vector.VectorSpecies;
public class VectorComputation {
private static final VectorSpecies<Integer> SPECIES = IntVector.SPECIES_PREFERRED;
public static int sum(int[] array) {
var length = array.length;
var loopBound = length - length % SPECIES.length();
var v0 = IntVector.zero(SPECIES);
var i = 0;
for (; i < loopBound; i += SPECIES.length()) {
var v = IntVector.fromArray(SPECIES, array, i);
v0 = v0.add(v);
}
int sum = v0.reduceLanes(VectorOperators.ADD);
for (; i < length; i++) {
sum += array[i];
}
return sum;
}
public static int sumMask(int[] array) {
var length = array.length;
var loopBound = length - length % SPECIES.length();
var v0 = IntVector.zero(SPECIES);
var i = 0;
for (; i < loopBound; i += SPECIES.length()) {
var v = IntVector.fromArray(SPECIES, array, i);
v0 = v0.add(v);
}
int sum = v0.reduceLanes(VectorOperators.ADD);
var mask = SPECIES.indexInRange(i, length);
var vMask = IntVector.fromArray(SPECIES, array, i, mask);
int sumMask = vMask.reduceLanes(VectorOperators.ADD);
return sum + sumMask;
}
}VectorComputationBenchmark
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
import java.util.Random;
import java.util.concurrent.TimeUnit;
@Warmup(iterations = 5, time = 5, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 5, time = 5, timeUnit = TimeUnit.SECONDS)
@Fork(value = 1, jvmArgs = {"--add-modules", "jdk.incubator.vector"})
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@State(Scope.Benchmark)
@SuppressWarnings("static-method")
public class VectorComputationBenchMark {
private final int[] array = new Random(0).ints(100_000, 0, 1_000).toArray();
@Benchmark
public int sum_loop_array(Blackhole blackhole) {
var sum = 0;
for (var value : array) {
sum += value;
}
return sum;
}
@Benchmark
public int sum_vector_array(Blackhole blackhole) {
return VectorComputation.sum(array);
}
}Benchmark
Lancer le benchmark
Branchez votre machine sur secteur puis :
cd ./maven-loom-intellij-boilerplate
mvn clean install
cd ./lab1/target
java -jar ./benchmarks.jarConclusions
REMEMBER: The numbers below are just data. To gain reusable insights, you need to follow up on
why the numbers are the way they are. Use profilers (see -prof, -lprof), design factorial
experiments, perform baseline and negative tests that provide experimental control, make sure
the benchmarking environment is safe on JVM/OS/HW level, ask for reviews from the domain experts.
Do not assume the numbers tell you what you want them to tell.
Benchmark Mode Cnt Score Error Units
VectorComputationBenchMark.sum_loop_array avgt 5 23,589 ± 2,136 us/op
VectorComputationBenchMark.sum_vector_array avgt 5 5,612 ± 0,284 us/opRessources
- https://mkyong.com/java/how-to-set-java_home-environment-variable-on-mac-os-x/
- https://fr.wikipedia.org/wiki/Processeur_vectoriel
- https://fr.wikipedia.org/wiki/Advanced_Vector_Extensions
- https://tel.archives-ouvertes.fr/tel-02406318/document
- http://p-fb.net/fileadmin/ParallelismeII/2016_2017/Cours Parallelisme II 2016-2017.pdf
- https://www.irisa.fr/archi09/defour.pdf