Cet article est en cours de rédaction, son contenu peut évoluer sans préavis et les informations qu'il contient peuvent manquer de précisions.

Avant-propos
Pourquoi la programmation concurrente ?
En une phrase, la programmation concurrente permet d'effectuer plusieurs opérations distinctes en même temps. Voici en quelques points ce que peut apporter la programmation concurrente :
- Une meilleur allocation des ressources: Les programmes sont souvent en train d'attendre des ressources venant de l’extérieur, il est largement préférable de pouvoir optimiser ce temps d'attente en exécutant d'autres programmes en même temps.
- Justesse/fairness: Il est bien souvent préférable lorsque deux appels simultanés a une ressource sont effectués (exemple deux utilisateurs demande un traitement) d’exécuter les deux actions simultanément plutôt que de faire d'abord un calcul, le renvoyer, puis faire le deuxième, le renvoyer...
- Un aspect pratique vous conviendrez qu'il est plus simple d'écrire plusieurs programmes qui exécutent une tâche plutôt qu'un seul programme qui gère tout.
- Meilleure gestion des éventements asynchrones…
Je vous invite à aller feuilleter ce livre de Bryan Goetz pour vous informer davantage sur le sujet.
Pourquoi Clojure ?
Clojure est né avec en tête l'idée de concevoir des programmes fonctionnels et concurrent. Clojure dispose d'un panel d'outils pour faire abstraction d'un ensemble de problèmes liés à la concurrence et vous permet d'écrire des programmes concurrents facilement.
Dans cet article nous allons faire état de ce qui se fait en matière de concurrence en clojure et effectuer un comparatif avec JAVA et Scala.
Prérequis
Si vous n'avez jamais touché à Clojure, je vous invite à consulter le précédent article sur le setup et la prise en main de Clojure.
Outils et structures de données concurrentes pour Clojure 🧰
Outils
Clojure est livré avec 3 mécanismes asynchrones de base. Passons-les en revue et étudions leur comportement.
Future
Tout d'abord, un coup d'œil sur code :
(let [result (future (Thread/sleep 3000)(+ 1 1))]
(println "The result is: " @result))
;; Will output after 3 seconds
;; The result is: 2
;; => nilLes future permettent d'invoquer une fonction sur un thread différent sans avoir besoin du résultat immédiatement.
Par exemple si vous voulez effectuer une tâche de manière non bloquante vous pouvez l'écrire comme ça :
(future (Thread/sleep 4000) (println "Le lapin fini la course"))
(println "La tortue fini la course")Vous l'aurez saisi, la petite sieste du lapin ira se faire sur un autre thread pour laisser la sérieuse tortue finir sa course.
Revenons à notre premier exemple.
Vous aurez remarqué le @ de @result. On appelle cette opération le déréférencement. D'ailleurs on aurait tout aussi bien pu utiliser (deref result).
Quand le thread distant fini son calcul, il garde le résultat en cache.
Le déréférencement permet de récupérer le résultat de la fonction exécutée sur un autre thread. Cet appel bloque jusqu'à avoir un résultat.
Une dernière petite chose à propos des futures : realized?
Cette fonction permet d'interroger un future pour savoir si le thread a fini son calcul.
Un dernier petit exemple :
(let [coffee (future (Thread/sleep 3000) :coffee-is-served)]
@coffee
(if (realized? coffee) (println "let's work bitc*es")))Promise
Là ou future délègue le calcul d'une fonction a un autre thread, promise permet de définir un endroit où "il y on pourrait récupérer un résultat", un bout de programme va fournir le résultat..
On peut représenter une promise comme une sorte de boite vide que l'on pourra ouvrir que lorsqu'elle sera pleine.
Un petit exemple pour commencer à jouer avec :
(do (def box (promise))
(deliver box :item-inside-box)
(println "Let's sneek a peek inside the box : " @box))Vous devriez désormais vous dire que…
(do (def box (promise))
(println "Let's sneek a peek inside the box : " @box)
(deliver box :item-inside-box))..devrait poser un petit problème (le déréférencement étant bloquant).
Demandons à un autre thread de surveiller la boite pendant que l'on continue nos affaires.
(do (def box (promise))
(future (Thread/sleep 1000) (println "Let's sneek a peek inside the box : " @box))
(deliver box :item-inside-box)
(println "hello from main thread"))
;; hello from main thread
;; => nil
;; Let's sneek a peek inside the box : :item-inside-boxDelay
Le delay permet de déclencher un calcul lorsque l'on en a besoin puis de déréférencer son résultat.
Par exemple si un producteur de musique a besoin d'un nouveau son pour l'été voilà comment il pourrait procéder :
(let [who-let-the-dogs-out
(delay (let [words (future (Thread/sleep 3000) :who-whowhowho)]
(println "it took 3sec to compute the rest of the song: " @words)
@words))]
(println "we need a catchy song")
(force who-let-the-dogs-out) ;; first evaluation
@who-let-the-dogs-out ;; cached value
(time @who-let-the-dogs-out)) ;; immediate no re-evaluationNotez que le premier dé-référencement a le même effet que force. Force n'est donc pas obligatoire.
En bref
future: Permet de déléguer un calcul à un autre thread, le calcul démarre lors de la déclaration.- Exemple IRL :
promise: Permet de définir un endroit où "il y on pourrait récupérer un résultat", un bout de programme va fournir le résultat.- Exemple IRL :
delay: Permet de différer un calcul d'un résultat. Le calcul démarre lors du premier usage, les usages successifs vont réutiliser le résultat calculé.- Exemple IRL :
Structures de données
Clojure est aussi livré avec des structures de données thread-safe qui permettent de s'affranchir en partie de la gestion des data-race et des questions d'exclusion mutuelles.
Il en existe 4 de base : atom agent var et ref
Concepts express.
- Les atoms permettent à plusieurs programmes d'avoir un accès synchronisé à une même ressource (imaginez une variable avec un vigile qui laisse un seul thread modifier son contenu à la fois)
- Les refs permettent un accès synchronisé à plusieurs ressources de manière coordonnée (ex : transaction).
- Les agents permettent de faire des opérations séquentielle sur une data-structure ( la subtilité avec l'atom est que le vigile après avoir vigoureusement recalé un candidat lui demande de bien vouloir aller faire la queue)
- Les Vars sont des variables globales disponible pour tous les threads.
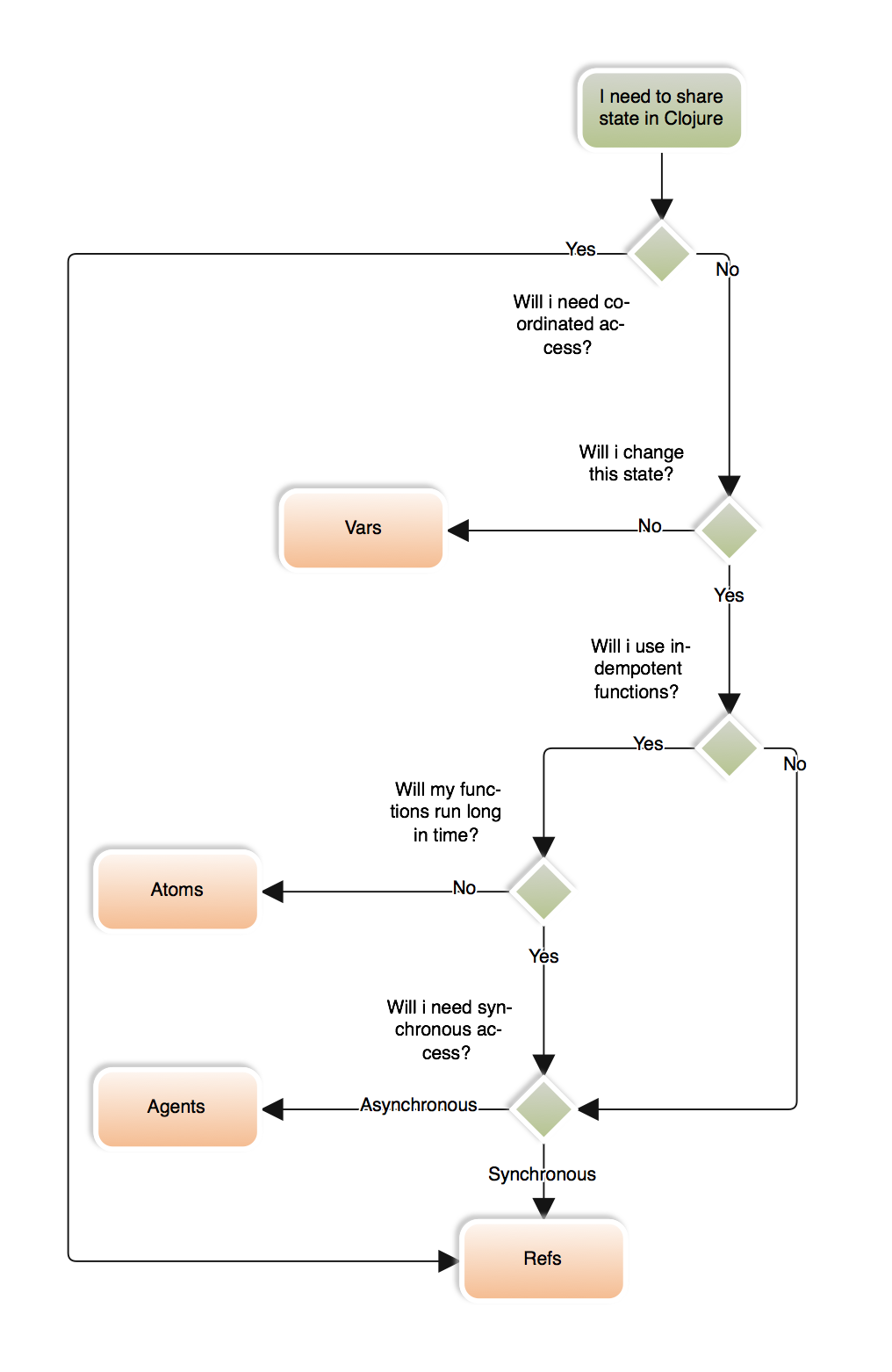
Toutes c'est structures concurrentes se définissent en terme de synchronicité et de coordination. Voilà quelques explications claires extraites du livre clojure programming (cf: ressources)
A coordinated operation is one where multiple actors must cooperate(or, at a minimum, be properly sequestered so as to not interfere with each other) in order to yield correct results. A classic example is any banking transaction: a process that aims to transfer monies from one account to another must ensure that the credited account not reflect an increased balance prior to the debited account reflecting a de-creased balance, and that the transaction fail entirely if the latter has insufficient funds.
Along the way, many other processes may provoke similar transactions involving thesame accounts. Absent methods to coordinate the changes, some accounts could reflectincorrect balances for some periods, and transactions that should have failed (or should have succeeded) would succeed (or fail) [improperly.In](http://improperly.in/) contrast, an uncoordinated operation is one where multiple actors cannot impact each other negatively because their contexts are separated. For example, two different threads of execution can safely write to two different files on disk with no possibility of interfering with each other.
Synchronization.
Synchronous operations are those where the caller’s thread ofexecution waits or blocks or sleeps until it may have exclusive access to a given context, whereas asynchronous operations are those that can be started or scheduled without blocking the initiating thread of execution.

Atoms
Tout d'abord, si vous êtes novice dans le monde de la concurrence, il y a des chances pour que l’intérêt d'une telle structure de données soit un peu floue.
Prenons l'exemple suivant :
(do (def hof (atom "hall of fame: "))
(def t1 (future (swap! hof (fn [current-state](Thread/sleep 100) (str @hof "Beyoncé ")))))
(def t2 (future (swap! hof (fn [current-state](Thread/sleep 100) (str @hof "Frankie Vincent ")))))
(def t3 (future (swap! hof (fn [current-state](Thread/sleep 100) (str @hof "Alain ")))))
@t1
@t2
@t3
(println @hof))Nous avons 3 artistes dont la carrière dure 100 ms avant d'atteindre la postérité et d'inscrire leur nom au Hall of fame.
Les outputs peuvent être variés :
hall of fame: Beyoncé Alain Frankie Vincent
hall of fame: Beyoncé Frankie Vincent Alain
hall of fame: Frankie Vincent Beyoncé Alain
...Pourquoi ?
Parce que chaque opération qui modifie l'atom est lancée sur un thread différent et chaque thread peut prendre la main.
Alors où est l’intérêt d'un telle structure ?
Si l'on reprend le concept :
Les atoms permettent à plusieurs programmes d'avoir un accès synchronisé à une même ressource (imaginez une variable avec un vigile qui laisse un seul thread modifier son contenu à la fois)
Dans le cas présent, si les atom permettait à n'importe qui de solliciter la ressource en même temps on se retrouverait avec des outputs comme ça :
hall of fame: AlBeyoFrankie Vinncé cent ainUn bel entrelacement.
Pour filer la métaphore, on appelle les opérations avec un vigile des opérations atomiques.
D'un point de vue technique, vous aurez surement reconnu le dé-réferencement avec @ qui permet d'obtenir l'état actuel de l'atom.
Parlons maintenant de swap!.
Cette fonction prend deux paramètres la référence de l'atom et une fonction. Elle permet de mettre à jour un atom, voilà quelques exemples :
;; Equivalent forms of atom swap
(swap! (atom 1) - 2 3)
(swap! (atom 1) #(- % 2 3))
(swap! (atom 1) (fn [num] (- num 2 3 ) ))
;; => -4
;; Update in atomic map
(swap! (atom {:a 1}) update :a - 5)
;; New empty atomic map
(def fish-atom (atom {}))
;; Add a key-value pair
(swap! fish-atom assoc :blowfish 1)
(println @fish-atom) ;; {:blowfish 1}
(swap! fish-atom update :blowfish inc) ;; {:blowfish 2}Notez que l'opération swap! retourne le dé-référencement de l'atom après le swap.
Refs
Maintenant que vous avez compris que certains accès a une ressource doivent se faire de manière synchronisée, vous pouvez imaginer que certains accès a plusieurs ressources se fasse de manière synchronisée.
L'exemple le plus concret est la transaction.
Prenons un simple exemple où je dispose de deux pièces et qu'un maitre sushitier sushi-iste vendeur de sushi dispose de deux sushis.
;; transaction
(def me (ref {:coins 2 :sushi 0}))
(def sushi-master (ref {:coins 0 :sushi 2}))
(defn trade [client server]
(dosync
(when (< 0 (:coins @me))
(alter me update :coins dec)
(alter me update :sushi inc)
(alter sushi-master update :coins inc)
(alter sushi-master update :sushi dec))))
(trade me sushi-master)
(println @me)
(println @sushi-master)Tous ces changements d'états simultanés ou transactions, sont:
- Atomiques : les changements d'états sont opérés entièrement ou pas du tout.
- Cohérents : dans notre cas un sushi appartiendra toujours soit au sushi-master, soit à moi, jamais aux deux ou à aucun.
- Isolés : les changements d'états sont effectués de manière séquentielle. Si deux threads tentent de modifier un ref commun, une des deux transactions sera refaite.
Un mot sur le vigile
Avant d'aller plus loin, regardons d'un peu plus près le mécanisme qui permet aux atoms et aux refs d'être atomiques et isolés : compare and set
Voilà un scénario typique de ce qui peut arriver quand plusieurs threads tapent sur les mêmes données :
(let [my-atom (atom 5)
s1 (future (Thread/sleep 1000) (+ 1 1))
s2 (future (Thread/sleep 1000) (+ 2 1))]
(swap! my-atom + @s1)
(swap! my-atom + @s2)
(println @my-atom))Vous l'aurez compris, il n'y a pas vraiment de vigile dans notre problème voilà ce qu'il peut se passer en réalité:
- t1 lis la valeur de l'atom (5) ajoute 1 (6) re-lis la valeur de l'atom. A ce moment là, soit la valeur n'a pas changé et le thread peut insérer 6 dans l'atom, soit la valeur de l'atom a changé et le thread recommence son calcul.
Sans ce mécanisme voilà un scénario possible:
- t1 lis la valeur de l'atom (5)
- t1 ajoute 1 (6)
- t2 lis la valeur de l'atom (5)
- t2 soustrait 1 (4)
- t2 met à jour l'atom (4)
- t1 met à jour l'atom (6)
Or dans notre cas, on veut que l'atom soit toujours égal à 5 une fois les deux opérations concurrentes effectuées.
Agents
Un agent gère/est responsable d’un état mutable (comme les autres structures concurrentes) indépendant. La subtilité avec les atoms où swap! est bloquant est que, dans le cas d'un agent, un thread s'arrange pour modifier le state indépendant en envoyant une action à l'agent (là où l'atom attend de pouvoir swap le state).
Une action est une fonction.
Ce qui est intéressant avec les agents, c'est que le thread demande un changement au state en envoyant une action et continue son exécution.
L'action envoyée est mise dans une file et finira par être exécuté sur le state.
Les agents sont fait pour des problèmes de concurrence légers, typiquement un exemple simple serait plusieurs threads qui essayent d'incrémenter un état.
Un petit exemple :
Imaginons une situation ou nous sommes dans un bureau de vote.
Un bureau de vote contient plusieurs urnes, mais un seul registre des votants (le fameux livret dans lequel vous signez après avoir voté)
Pour aller plus vite il est convenu qu'un votant doive voter puis aller faire la queue pour s'inscrire au registre et laisser sa place au prochain votant.
(let [register (agent [])
voters-voting
(fn [n ballot]
(when (< 0 n)
(println "A VOTÉ !")
(send register conj {:ballot ballot
:voter n}) ;; send voter to queue for registration
(recur (dec n) ballot)))
ballot
(fn [message]
(future (Thread/sleep 1000) (voters-voting 3 message)))
ballot1 (ballot "first ballot")
ballot2 (ballot "second ballot")
ballot3 (ballot "third ballot")]
@ballot1
@ballot2
@ballot3
@register)Si vous exécutez plusieurs fois le code, vous pourrez remarquer que parfois le dé-référencement de register n'est pas exactement le résultat espéré: certains voteurs manquent.
En effet, la ressource critique register est déréférencé une fois que chaque future a retourné.
Or dans le cadre d'un agent, la méthode send retourne immédiatement et met le changement d'état dans une file d'attente.
Si vous souhaitez surveiller l'état d'un agent, vous pouvez utiliser la fonction add-watch
(let [register (agent [])
_ (add-watch register nil (fn [_ _ _ v] (println "register:\n" v)))
voters-voting (fn [n ballot]
(when (pos? n)
(send register conj {:ballot ballot
:voter n}) ;; send voter to queue for registration
(recur (dec n) ballot)))
ballot (fn [message]
(future (Thread/sleep 1000) (voters-voting 3 message)))
ballot1 (ballot "first ballot")
ballot2 (ballot "second ballot")
ballot3 (ballot "third ballot")])Output:
regiter:
[{:ballot first ballot, :voter 3}]
regiter:
[{:ballot first ballot, :voter 3} {:ballot first ballot, :voter 2}]
regiter:
[{:ballot first ballot, :voter 3} {:ballot first ballot, :voter 2} {:ballot third ballot, :voter 3}]
regiter:
[{:ballot first ballot, :voter 3} {:ballot first ballot, :voter 2} {:ballot third ballot, :voter 3} {:ballot second ballot, :voter 3}]
regiter:
[{:ballot first ballot, :voter 3} {:ballot first ballot, :voter 2} {:ballot third ballot, :voter 3} {:ballot second ballot, :voter 3} {:ballot first ballot, :voter 1}]
regiter:
[{:ballot first ballot, :voter 3} {:ballot first ballot, :voter 2} {:ballot third ballot, :voter 3} {:ballot second ballot, :voter 3} {:ballot first ballot, :voter 1} {:ballot third ballot, :voter 2}]
regiter:
[{:ballot first ballot, :voter 3} {:ballot first ballot, :voter 2} {:ballot third ballot, :voter 3} {:ballot second ballot, :voter 3} {:ballot first ballot, :voter 1} {:ballot third ballot, :voter 2} {:ballot second ballot, :voter 2}]
regiter:
[{:ballot first ballot, :voter 3} {:ballot first ballot, :voter 2} {:ballot third ballot, :voter 3} {:ballot second ballot, :voter 3} {:ballot first ballot, :voter 1} {:ballot third ballot, :voter 2} {:ballot second ballot, :voter 2} {:ballot third ballot, :voter 1}]
regiter:
[{:ballot first ballot, :voter 3} {:ballot first ballot, :voter 2} {:ballot third ballot, :voter 3} {:ballot second ballot, :voter 3} {:ballot first ballot, :voter 1} {:ballot third ballot, :voter 2} {:ballot second ballot, :voter 2} {:ballot third ballot, :voter 1} {:ballot second ballot, :voter 1}]Core/async
Core async est une bibliothèque pour la concurrence simple et efficace.
Ajoutez la lib dans les dépendances de votre projet, si vous utilisez Leningein ajoutez dans :dependencies :
[org.clojure/core.async "1.3.610"]Puis dans votre namespace importez la lib pour jouer avec..
(ns playsync.core
(:require [clojure.core.async
:as a
:refer [>! <! >!! <!! go chan buffer close! thread
alts! alts!! timeout]]))Un exemple simple pour commencer:
(do (def echo-chan (chan))
(go (println (<! echo-chan)))
(>!! echo-chan "queued !"))Dans ce petit programme, vous commencez par instancier un chan qui n'est ni plus ni moins qu'une file tampon non bornée. C'est à dire que vous pouvez mettre des choses dans ce channel un peu comme vous le feriez dans un pipe en C.
Ensuite le go block vous permet de lancer des opérations dans un thread pool, c'est a dire un ensemble de thread qui vont se répartir les taches. pour paralléliser des opérations avec core async vous avez juste besoin d'écrire go
L'opération <! signifie que prenez dans le channel de manière non-bloquante. Si il n'y a rien dans le channel, vous n'allez pas réserver un thread sous prétexte qu'il n'y a rien dans le channel (laissez le faire autre chose)
Buffering
Vous pouvez tout à fait décider d'avoir une file bloquante bornée pour vous en servir de tampon, a ce moment là il vous suffira juste de dimensionner un channel et d'utiliser les opérateur bloquants <!! et >!!
Exemple:
(def buffer (chan 2))
(>!! buffer "queued !")
; => true
(>!! buffer "queued !!")
; => true
(>!! buffer "blocks !!!")
; This blocks because the channel buffer is fullSi vous souhaitez lancer une opération bloquante sur un autre thread, vous pouvez utiliser :
(thread (println (<!! echo-chan)))
(>!! echo-chan "mustard")Le mot de la fin…
Avec ces outils, vous devriez être en mesure d'avoir une vue d'ensemble sur les outils disponible pour faire de la programmation concurrente avec Clojure.
Dans un prochain article, nous comparerons certains problèmes de concurrence implantés en Java, Scala et Clojure.
Ressources
- https://fr.wikipedia.org/wiki/Catégorie:Programmation_concurrente
- https://www.nurkiewicz.com/2013/03/promises-and-futures-in-clojure.html
- https://clojure.wladyka.eu/posts/share-state/
- http://www.clojurebook.com/
- https://www.youtube.com/watch?v=nDAfZK8m5_8
- https://github.com/guihardbastien/Go-Books/blob/master/concurrency/Java Concurrency in Practice.pdf