Il est mercredi 17h. Nous partons de la Gare Du Nord en direction d'Amsterdam afin d'assister au Process Mining Camp 2019 qui a lieu du 20 au 21 juin à Eindhoven. Tout juste le temps de goûter au kapsalon, une spécialité locale, avant de nous retrouver à cette conférence de deux jours au sein de l'Eindhoven University of Technology et animée par l'entreprise Fluxicon.

La culture du vélo aux Pays-Bas n'a jamais été aussi vraie qu'à Eindhoven 🚲
Le process mining, quésaco?
Process Mining Camp 2019 est une conférence tournant autour du process mining... Le process mining, pour ceux qui ne connaissent pas, a pour vocation d'utiliser la data (sous forme d'event data), afin de créer des modèles composés de processus que l'on va pouvoir par la suite analyser et interpréter. Un event doit au moins contenir les informations suivantes pour être utilisé en process mining : un case ID, un timestamp et une activity. Ceci n'est qu'une brève introduction mais je vous invite à vous renseigner sur le process mining via le cours sur Coursera et le blog de fluxicontous deux des mines d'or d'information. Un article de blog introduisant le process mining sera aussi bientôt présent sur notre blog alors ouvrez l’œil et le bon 😉 !
Rien de mieux qu'un exemple pour comprendre ce qu'est le process mining. Imaginons un use case qui pour la plupart d'entre nous est assez familier, une issue Github. Une issue peut être vue comme un process puisqu'il "raconte une histoire".
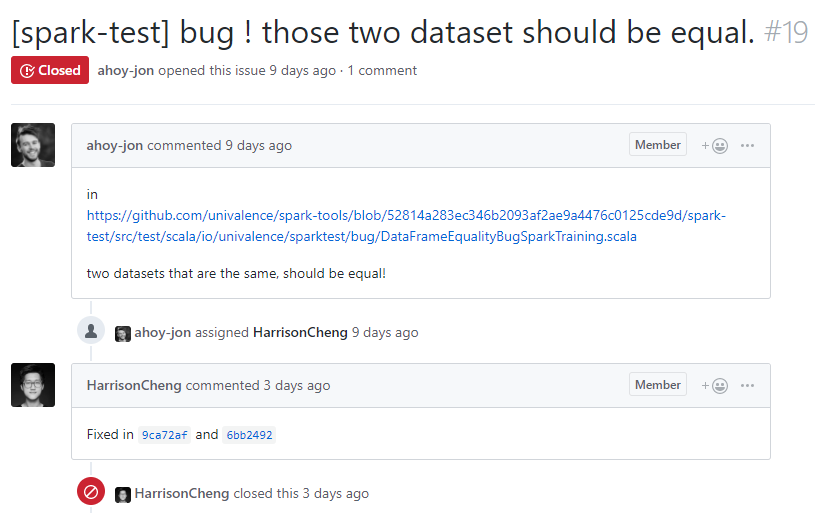
Cet exemple vient de notre projet open source spark-tools. Nous pouvons le traduire en une suite d’événements ayant un début et une fin ainsi :
- Le case ID dans ce cas serait #19, soit l'ID de l'issue.
- Les activities seraient l'ouverture de l'issue, le ou les commit(s) pour résoudre l'issue et la fermeture de l'issue.
- Les timestamps bien qu’imprécis car pas à la seconde prêt dans ce cas serait 19/06/2019, 24/06/2019, 24/06/2019 (2 commits) et 25/06/2019.
- Les resources seraient respectivement ahoy-jon, HarissonCheng, HarissonCheng et HarissonCheng (2 commits et une fermeture) c'est-à-dire les personnes qui ont fait l'action.
Voici l'event data que nous obtiendrions suivi de son model process respectif généré par Disco:
| Case ID | Activity | Timestamp | Ressource |
|---|---|---|---|
| 19 | ouverture de l'issue | ahoy-jon | |
| 19 | commit | HarissonCheng | |
| 19 | commit | HarissonCheng | |
| 19 | fermeture de l'issue | HarissonCheng |
Nous somme ici témoins d'un exemple d'une simplicité inexistante. Pour comprendre l'importance du process mining il faut s'imaginer avoir des centaines de milliers d'issues toutes entreposées dans un CSV (par exemple), ayant toutes une histoire plus ou moins différente rendant la compréhension générale du process impossible. C'est à ce moment que le process mining devient une valeur ajoutée inestimable puisqu'une fois le process model créer, on peut observer en rejouant les traces le comportement général du processus, analyser les bottleneck, filtrer en bloquant par exemple un des process, regarder le process qui prend le plus de temps à être réalisé, se référer au temps pour détecter une mauvaise gestion du processus à un endroit ou à un autre etc. Valeur prouvée de mainte et mainte fois lors des différents talks que nous avons eus le premier jour.
Le process mining notre ami pour la vie
Nous avons été bien servis la première journée puisque nous avons eu la chance d'assister à pas moins de neuf talks autour du process mining, dont une réalisée par Wil van der Aalst, un acteur majeur dans le domaine, à propos de l'éthique au sein du process mining.

Opening du Process Mining Camp par Anne Rozinat de Fluxicon
Chaque talk nous a présenté un cas d'utilisation du process mining dans des milieux professionnels variés ayant tous des problématiques différentes. Cela nous a permis de nous rendre compte de l'importance du process mining, dès lors que nous avons un processus qui a un début et une fin et qui se fait en plusieurs étapes. Parmi ces talks, trois d'entre eux nous ont particulièrement interpellés.
Boris Nikolov de chez Vanderlande nous a fait part de son expérience à travers l'optimisation de deux chaînes de traitement. Il a ainsi illustré les larges possibilités qu'offrent Disco, l'outil de process mining phare. Il a expliqué comment interpréter ces cas pour en ressortir des conclusions orientées métier. Il nous a montré comment, à partir de l'exploration d'un process model, il valide et optimise les différents processus logistiques, que ce soit au sein d'un aéroport avec le scénario décrivant la durée de vie d'une valise de l'embarquement à l’atterrissage ou d'un entrepôt de colis où le scénario se concentre sur la sélection du colis et son transport jusqu'à sa destination.
Hadi Sotudeh quant à lui a su nous montrer que le process mining pouvait être adapté et toucher à des domaines divers et variés tels qu'un match de foot. Au premier abord, cela semble farfelu d'utiliser le process mining pour analyser un match de foot. Mais avec un peu d'imagination, il est très facile de voir un match de foot comme un process ou chaque action menée par une équipe est une suite d'activités et dont la "ressource" serait le nom du joueur qui effectue l'action. Ce genre de process lui a par exemple permis de répondre à la question suivante : comment cette équipe de foot (l'Iran) joue, en analysant les différents patterns le long du match.
Wil van der Aalst a tenu à clôturer la journée par un talk bienveillant ayant pour but de nous mettre en garde sur le process mining et de nous amener vers de la data "plus verte". Comme bien d'autres domaines liés à la data, le process mining se heurte à des problèmes de confusion entre causalité et corrélation et de vie privé, point majeur aujourd'hui notamment depuis l'arrivée de la RGPD qui a déjà été présenté sur notre blog par Harrison Cheng.
Il est temps de mettre la main à la pâte
La deuxième journée nous a permis de mettre en pratique les concepts vus le jour précédent à travers quatre workshops tous centrés sur Disco, le logiciel créé par Fluxicon. Celui-ci permet à l'aide de logs de mettre en place un process model et d'y simuler les différentes traces.
Les quatre workshops étaient les suivants :
- How to improve processes in the digital age?
- From ERP system to dataset: How do I prepare a useful event log?
- How can I combine process mining with RPA?
- What questions can I answer with process mining?
Nous avons fait le choix de nous répartir dans les différents workshops. Pour ma part, je suis allé au premier workshop donné par Rudi Niks, un des ingénieurs de Fluxicon. Durant ce workshop, on nous a montré comment le process mining pouvait être utilisé dans chaque étape du DMAIC (Définir, Mesurer, Analyser, Améliorer/Improve et Contrôler) qui nous a été présenté comme une méthode de résolution de problème qui repose sur les cinq principes cités ci-dessus. À travers un cas concret comportant l'étude d'un process visant à convaincre des personnes de s'inscrire pour une assurance, on a pu parcourir ces étapes et arriver à la conclusion que le process mining est un excellent complément pour comprendre et analyser la complexité d'un process.

La salle du workshop 4 où était présent deux de nos ingénieurs, Harrison Cheng et Philippe Hong
Les bonnes histoires ont une fin

Il est vendredi 14h, nous repartons déjà vers Paris des idées plein la tête. Ce voyage a été très chargé, mais aussi et surtout très bénéfique. Nous avons eu en effet la chance de rencontrer la communauté du process mining, une communauté remplie de bonnes intentions et nous remercions l'équipe de Fluxicon : Anne Rozinat, Christian W. Günther et Rudi Niks pour avoir organisé ces deux journées ainsi que toute les personnes présentes à cette conférence.
Merci ❤🐇