Le Process Mining Camp 2019 nous a fait goûter à l'univers du process mining. Dans le dernier article, nous avons pris le parti de nous concentrer sur l’expérience vécue à Eindhoven. Ainsi, nous revenons aujourd'hui pour vous présenter ce qu'est le process mining de manière plus détaillée et concrète. L'objectif étant de vous faire découvrir les bases de ce que nous pensons être un outil très intéressant.
Le process mining peine à se développer en France. Et pourtant, il apporte énormément de visibilité à un process. Dans un monde où la data est devenue reine, le process mining n'a jamais autant eu sa place. Il créé le lien entre l'analyse des processus et la gestion de la data. Chaque process est composé d'actions qui s’enchaînent, formant ainsi une trace ayant un début et une fin. Ces traces sont à la source du process mining, puisque c'est grâce à elles que nous allons pouvoir générer un process model, comme le schéma ci-dessous :
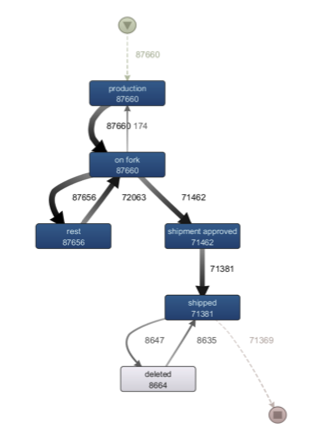
Image tirée du logiciel Disco prise du blog fluxicon
Ceci n'est qu'une simple introduction. Ainsi, si vous vous sentez l’âme d'un explorateur, je vous conseille de vous rendre sur le blog de Fluxicon qui se consacre entièrement sur le process mining, regroupant des interviews d'experts, des cas réels et des techniques utilisées dans le domaine.
Glossaire
Le process mining étant un peu verbeux, voici un glossaire expliquant chaque mot technique :
- Event ou event log : un event est une action émise à un temps donné ayant ainsi au moins un timestamp (le moment auquel l'action a été produite), un case ID (l'id du process) et une activity (le type d'action).
- End to end process : un process est une suite d’événements liés de manière chronologique entre eux afin de raconter son déroulement dans le temps.
- Event data ou logfiles : fichiers constitués d'une multitude d'event généralement stocker dans un tableau où chaque ligne est un event.
- Trace ou case : une trace est la suite d'actions décrivant un end to end process.
- Process model : représentation systémique d'un end to end process généré grâce au logfiles.
- ProM/Disco: logiciels de process mining générant un process model et fournissant des outils d'analyse sur ce dernier. Il en existe une multitude que nous n'avons pas eu le temps de consulter. Une bonne partie d'entre eux peuvent être trouver ici.
De l'event data...
L'action de créer un process model à partir de traces se nomme "play-in". En réalité, il y a trois types de relations entre la data et les process :
- les relations play-in, : on créé un modèle depuis des traces existantes
- les relations play-out : on simule des traces (end to end process) depuis un modèle existant
- les relations replay : on rejoue des traces sur un modèle existant (fait à la main ou généré depuis des traces)
Cependant, généralement lorsqu'on parle de process mining, on se réfère plus aux relations de type play-in et replay. Le but étant d'utiliser un tableau rempli d'event ou log, de générer le process model correspondant puis d'effectuer certaines analyses telles que l'identification de bottleneck (activité bloquante ou surchargée), afin de mieux comprendre le process et de pouvoir l'optimiser.
Dans le cas du process mining, nous ne pouvons pas utiliser n'importe qu'elle type de data. Seul les "event data" sont acceptés et ces derniers composés d'événement respectent aux moins trois propriétés :
- Chaque événement doit contenir un case ID, l'ID du process en cours. Ce peut être le numéro d'une commande, le nom d'un étudiant, etc.
- Chaque événement doit contenir un timestamp, la date à laquelle l'événement à été effectué.
- Chaque événement doit contenir un activity name, l'activité qui a été effectuer à cette date.
Deux autres propriétés sont quant à elles dispensables ainsi :
- Chaque événement peut contenir une ressource, la personne qui a effectué l'action (à noter que dans certains cas, la personne effectuant l'action apparaît dans le case ID lui-même).
- Chaque événement peut contenir d'autres data complémentaires.
Pour appuyer mes propos, rien ne vaut un exemple. Cet exemple à été fortement inspiré d'un exemple donné dans le cours Coursera à propos du process mining que je vous invite à aller consulter.
| order number | action | timestamp | User | product | quantity |
|---|---|---|---|---|---|
| 1 | register | 26/06/2019-09.25 | John Doe | 🚗 | 2 |
| 2 | register | 26/06/2019-09.34 | John Doe | 🚀 | 1 |
| 1 | check stock | 26/06/2019-09.43 | Mickael Bae | 🚗 | 2 |
| 2 | check stock | 26/06/2019-09.57 | Mickael Bae | 🚀 | 1 |
| 2 | ship order | 26/06/2019-10.02 | Sarah Cabo | 🚀 | 1 |
| 3 | register | 26/06/2019-10.12 | John Doe | 🚀 | 1 |
Si l'on reprend l'exemple ci-dessus, une façon de construire notre process serait de voir l'order number comme étant notre case ID, l'action comme étant l'activity, le timestamp comme étant le timestamp, le user comme étant la ressource et le product/quantity comme étant des données supplémentaires (je parle ici de façon de construire notre process car on aurait très bien pu analyser ces logs en prenant les user comme étant notre case ID par exemple). Maintenant que nous avons définit nos différentes colonnes nous sommes prêt à passer à l'étape suivante.
... au Process Model
Avoir l'event data est un bon début, mais cela n'est qu'un début. Une fois notre event data remplit de millier de logs, il faut pouvoir générer le process model lui correspondant. Pour se faire, des algorithmes ont été créés générant ainsi depuis l'event data le process model correspondant. Le plus simple d'entre eux est l'alpha algorithm. Cependant, sa simplicité implique aussi certaines limitations. Nous n'allons pas rentrer dans les détails ici. Si le sujet vous intéresse, le cours Coursera sur le process mining rentre dans les détails. Dans notre cas, nous allons générer notre process model grâce un outil : Disco. Importer un fichier sur Disco est très simple.
L'exemple ci-dessus n'est pas assez complet pour pouvoir créer un véritable process model ainsi prenons un autre jeu de données qui provient du Business Processing Intelligence Challenge 2014, dans lequel les organisateurs donnent plusieurs fichiers à partir desquels les participants doivent y extraire des informations, afin d'avoir une vision globale de la situation. Nous allons nous concentrer pour la découverte du logiciel Disco sur le fichier nommé Incident activity record.
Commençons par l'importer afin de convertir les différents log en un process model :
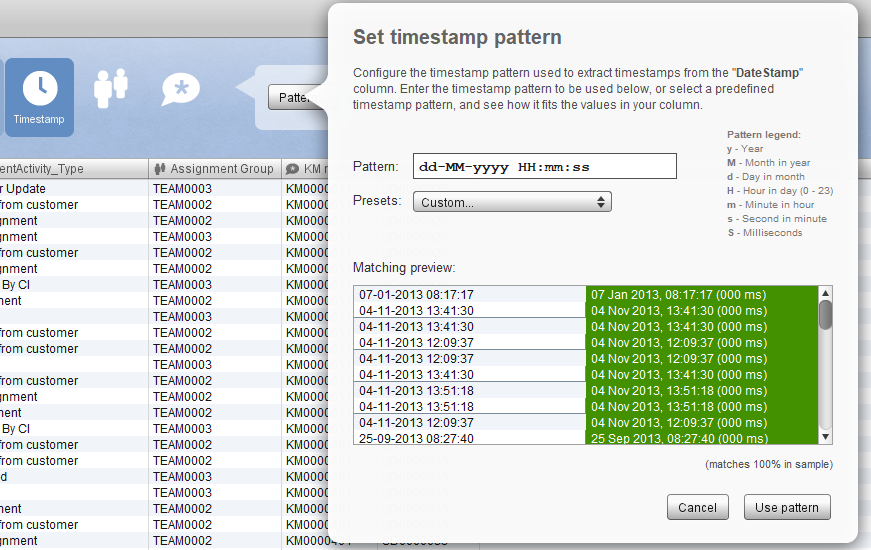
Il faut préciser le type des colonnes. Dans notre cas, ce n'est pas bien compliquer : l'incident ID est le case ID, DateStamp le timestamp, incidentActivity_Type l'activity, Assignment Group la ressource et les autres données ne sont que des compléments. N'oubliez pas de convertir vos timestamps dans un format qui correspond à votre data. Une fois cela fait, on peut générer notre process model:
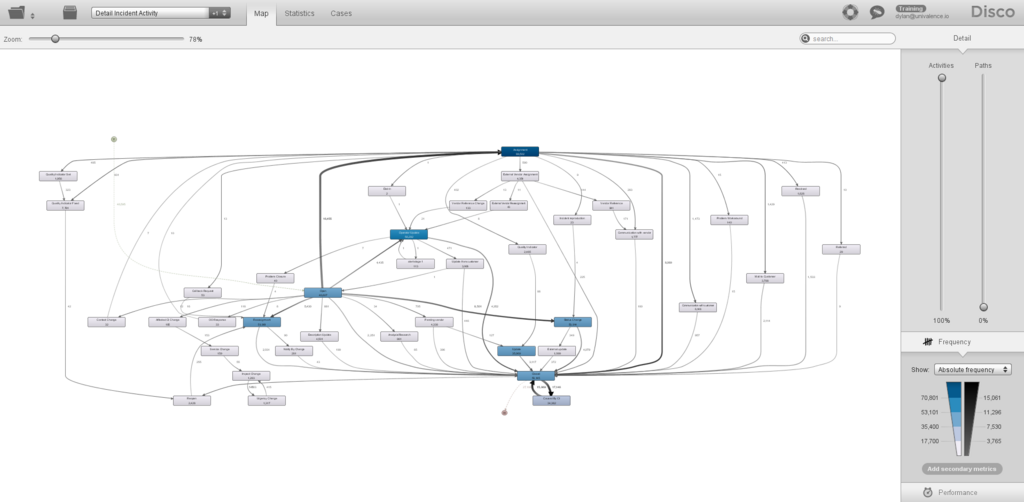
Le process model correspondant semble être totalement chaotique. Ceci s'explique surtout par le fait que nous avons de la data issue d'un cas réel. Les process dans la réalité ne sont pas totalement linéaires et nous nous retrouvons souvent avec des activités se produisant que très rarement et donc n'ayant pas une importance primordiale pour nos différentes analyses. Pour y pallier, nous avons plusieurs possibilités. Soit nous filtrons notre process model en prenant par exemple que les traces passant par une activité donnée, soit nous pouvons et c'est ce que nous allons faire ici réduire le nombre d'activités pris en compte. De base, le process model nous montre la totalité des activités. Vous pouvez remarquer que certaines d'entre elles ne sont sollicités qu'une quinzaine de fois sur environ une centaine de milliers de cas. Ce qui est négligeable. On réduit juste le pourcentage à droite de notre process model. Et nous obtenons ainsi le model suivant:
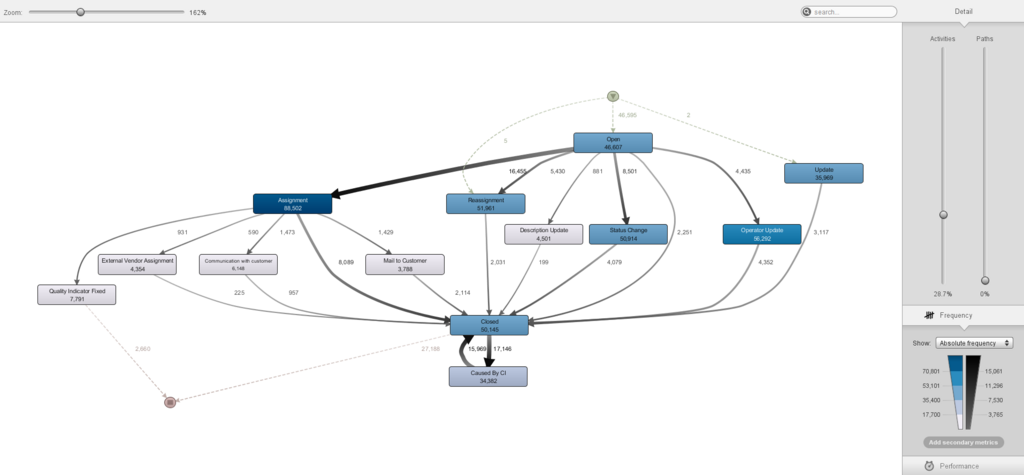
Ce model donne une vision globale du process que nous pouvons par la suite analyser. La phase d'analyse peut se faire à plusieurs niveaux que ce soit au niveau du process model, au niveau de l'onglet statistics, en utilisant des filtres, etc. On peut dans notre cas, à titre d'exemple, regarder la performance de nos activités ou encore analyser la performance de chaque équipe résolvant les différents problèmes. Qu'importe l'analyse, elle doit répondre à des questions posées au préalable et ceci est la résultante d'une compréhension du métier et de ses divers aboutissants.
Conclusion
Le process mining est une technique très puissante et très intéressante lorsqu'un process rentre en jeux. Des outils puissants existent et nous permettent de visualiser nos logs à travers un process model plus ou moins complexe et dans le cas de Disco totalement modulable. Néanmoins, ce dernier n'est pas magique et certains points sont à prendre en considération. Lors d'un talk de Wil van der Aalst au Process Mining Camp 2019, on nous a mis en garde face à la différenciation entre causalité et corrélation. À cela, je rajouterais une vigilance lors de la data préparation et surtout beaucoup de recul lors de l'analyse d'un process puisqu’il est très facile de prendre un bouc émissaire, d'identifier un bottleneck bloquant la fluidité du process sans pour autant prendre en compte les difficultés du terrain.