Dans mon apprentissage de Delta Lake, un format de stockage open-source qui permet notamment d’avoir les propriétés ACID sur des systèmes de stockage qui de base ne les ont pas, entre autres, on m’a parlé de Z-Ordering et de Liquid Clustering pour améliorer les performances des requêtes. Mais que sont-ils ? À quoi peuvent-ils servir ? Nous vous expliquerons tout cela dans cet article.
Z-Ordering
Data-skipping
Un des aspects qui améliore les performances, est le data-skipping (ou file-skipping), en effet la lecture d’un fichier pour le transférer dans la mémoire est coûteux, donc moins nous lisons de fichier, plus la requête sera performante. Pour cela Delta utilise les métadonnées de ses fichiers pour savoir si le fichier doit être lu ou non, on y trouve le minimum et le maximum de chaque colonne par fichier ce qui permet de le déterminer.
Compaction
Un autre aspect, est la réduction de nombre de fichier avec la compaction, en compactant la table, c’est à dire que moins de fichier seront à lire.
Illustration
Le Z-Ordering utilise ces aspects d’amélioration de performance, en effet si nous utilisons le Z-Order selon une colonne id par exemple, alors toutes les occurrences d’un même id vont être colocalisés au sein d’un fichier mais de façon ordonnée et les plages d’id de chaque fichier sera plus petite.
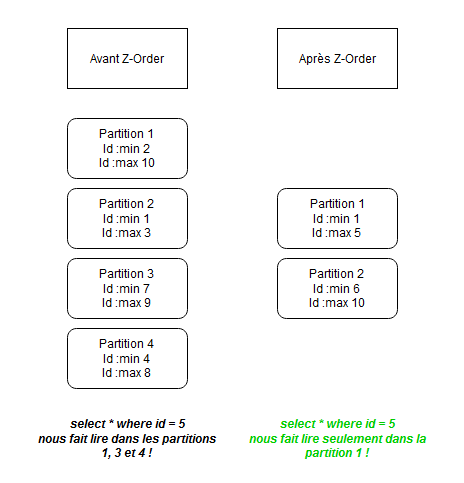
Dans l’exemple simplifié ci-dessous, à droite nous avons notre donnée non ordonné repartie sous 4 partitions, on voit dans les métadonnées de chaque partition le minimum et le maximum de la colonne id.
Après l’application du Z-Order, à droite, nous n’avons plus que 2 partitions, et elles sont ordonnées par plage, la partition 1 contient les ids entre 1 et 5 et la partition 2 contient ceux entre 6 et 10.
Imaginions que nous voulions faire un SELECT * FROM table where id = 5 dans le premier cas nous aurions lu un total de trois partitions contre un après le Z-Order.
OK, mais comment cela fonctionne à partir de 2 colonnes ?
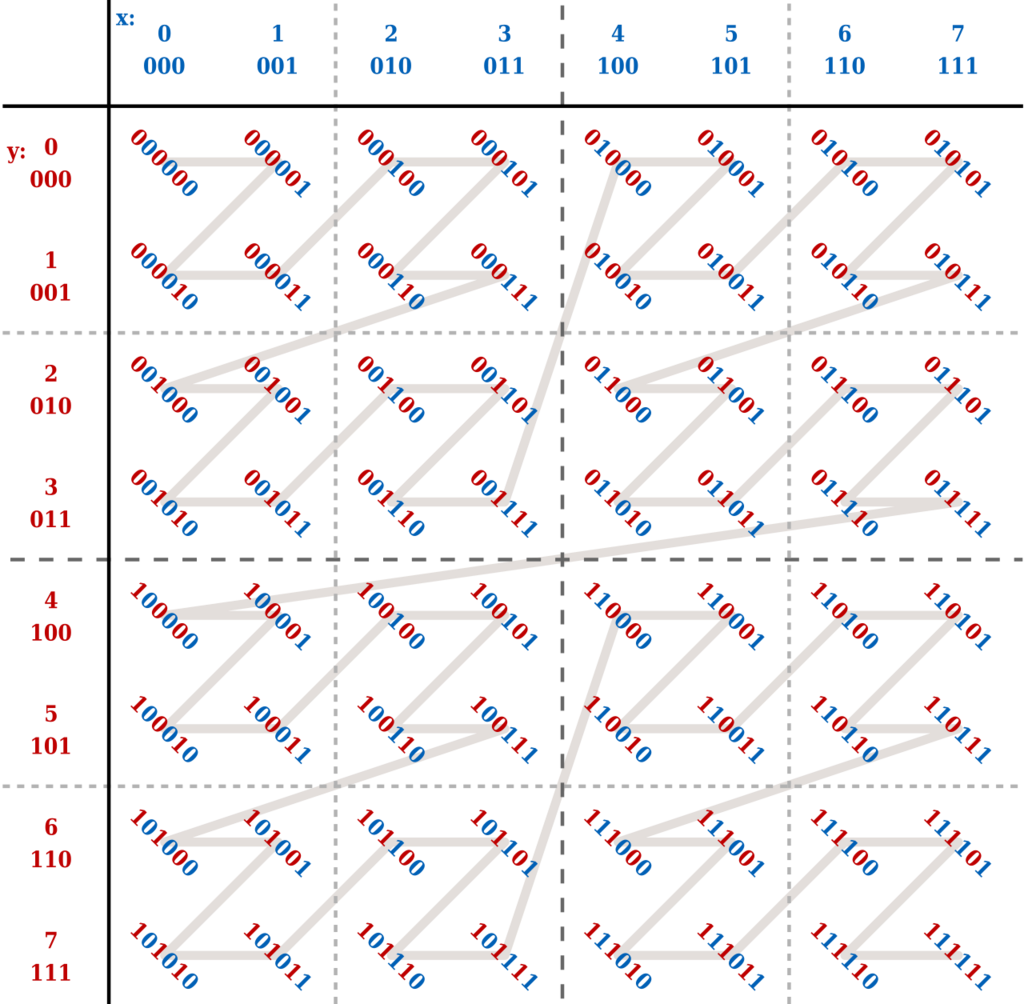
Imaginez que nous vous utiliser le Z order sur les colonnes x et y, l’algorithme va calculer les coordonnées Z (ou z-values) de la façon suivante, il va d’abord changer chaque valeur de colonne en binaire, puis va interchanger la valeur binaire de x et y pour donner z, exemple :
- Si l’on prend x = 3 (011) et y = 7 (111) on obtiendra z = 47 (10 1 111)
Si nous parcourrons les valeurs de z dans l’ordre croissant, nous obtenons le schéma ci-dessus, qui étonnement forme aussi un Z (à plusieurs niveaux en plus) ! On appelle cela le Z-Order curve (ou Courbe de Lebesgueen français).
L’emploi de la commande du Z-Order va appliquer ce qu’on a vu pour une colonne à ces coordonnées Z pour réorganiser notre table, avec des plages de coordonnées Z sous la même partition (sur l’illustration, on peut imaginer que chaque carré de pointillé devient une partition), donc c’est un peu comme transformer le problème à plusieurs dimensions en un problème à une dimension.
Comparaison
Voici un exemple donné dans le design sketch de la fonctionnalité.
Ici, chaque fichier à 4 occurrences, à gauche nous avons le tri naturel, on ordonne d’abord par x puis par y, et à droite le Z-Order comme sur la figure précédente.
Voici ce qui se passerait avec la requête SELECT * FROM points WHEREx = 2ORy = 3
- À gauche, nous scannons 9 fichiers avec 21 occurrences qui ne nous intéressent pas.
- À droite, nous scannons 7 fichiers avec 13 occurences qui ne nous intéressent pas.
C’est pourquoi avec cette courbe nous avons un data-skipping plus efficace pour un prédicat qui contient x et y.
Quand l’utiliser ?
Il faut faire le Z-Order si vos colonnes sont souvent utilisées dans vos requêtes et si elles ont une haute cardinalité (beaucoup de valeurs distinctes).
Le prérequis est que vos colonnes doivent avoir la collecte de statistiques activée (pour utiliser les métadonnées afin d’enclencher le data-skipping).
Il ne faut pas non plus ajouter chaque colonne, en effet augmenter la dimension fera diminuer les performances si l’on utilise très peu les colonnes ajoutées dans nos prédicats.
Le Z-Ordering est aussi compatible avec le Hive-Style-Partitioning (où les valeurs de la colonne de partition seront utilisés comme dossier pour séparer les fichiers), dans le sens où l’on peut réordonner les fichier au sein de ses dossiers, mais on ne pourra pas utiliser la colonne de partition pour le Z-Ordering.
Par contre la commande doit être ré-exécuté assez régulièrement, quand nous avons de nouvelles données par exemple, l’opération est coûteuse, en effet on réécrit tous les fichiers ce qui peut en faire aussi un désavantage, il faut aussi se souvenir des colonnes utilisées pour le Z-Order. Aussi si l’opération d’optimisation échoue, il faut la recommencer.
Mais justement nous allons voir qu’une autre fonctionnalité existe et arrive avec le Liquid Clustering qui remédie à ses limitations.
Pour aller plus loin
Pour plus d’informations, n’hésitez pas à regarder la documentation, et l’article officiel de Delta Lake, ainsi que leur notebook. Par curiosité allez voir le sketch pour créer la fonctionnalité. Cette vidéo explicative est pas mal aussi.
Liquid Clustering
L’annonce de Delta Lake version 3.0 en Juin 2023 s’est vu accompagné de la venu du Liquid Clustering, qui simplifierait la façon d’obtenir les meilleurs performances pour nos requêtes et son coût pour l’obtenir en même temps que la donnée grandit.
Aujourd’hui avec Delta Lake 3.1, la fonctionnalité est présente mais est toujours en expérimentation.
Toutes les illustrations proviennent de leur Design Doc .
Nous avions vu que le Hive-Style-Partitioning et le Z-Order pouvait cohabiter et être une bonne approche pour partitionner nos tables. Mais ils viennent avec leur limitation :
- Le Hive-Style-Partitioning permet de cloisonner nos fichiers, mais si les colonnes de partitions ont une haute cardinalité cela va créer plusieurs petits fichiers que l’on ne peut combiner. Changer de stratégie de partitions peut être difficile, donc moins adaptable à la façon dont nous requêtons.
- Pour le Z-Order, toutes les limitations vu plus tôt.
L’idée avec le Liquid Clustering est de supprimer toutes ses limitations :
- En mettant les colonnes de clustering directement au moment de la création de la table
- elles seront persistées dans les métadonnées
- on peut changer les colonnes de clustering pour s’adapter aux nouvelles stratégie de requêtage ou autre, sans pour autant tout recalculer.
- Le clustering se fait de manière incrémentale, sans toucher à l’intégralité des données
Courbe de Hilbert
Avec le Z-Order, nous avons vu l’application de la Z-Order curve (Courbe de Lebesgue), ici dans l’image ci-dessous provenant de leur Design Doc, ils veulent utiliser une autre courbe qui est la Courbe de Hilbert où la distance entre chaque point selon la courbe est de 1.
De manière similaire au Z-Order, on peut les partitionner par 4 en suivant la courbe.
Comparaison
Sur le schéma ci-dessus nous avons au final un même partionnement que pour le Z-Order, donc en quoi est-ce que la Courbe de Hilbert est mieux ?
Une bonne illustration est de voir ce qui se passe si nous partitionnons avec 6 éléments en suivant la courbe de chacun :
Avec Z-Order :
Le problème est bien visible ici, sur la partition entourée rouge, en effet avec Z-Order nous avons des “sauts” ce qui a pour impact d’avoir une trop grand plage de données, ici on aurait :
- pour y : min = 3 et max = 5
- mais pour x : min = 0 et max = 7 !
Avec Courbe de Hilbert :
Avec cette courbe, la distance entre toujours réduite, l’écart maximal est de 4.
Avec Z-Order, il y aurait un fichier qu’on lirait tout le temps si on cherche n’importe quel x, alors qu’avec l’autre courbe il n’existe pas de tel fichier.
Incremental Clustering
Le concept tourne autour de ZCube : un groupement de fichier produit par le même job OPTIMIZE.
Il y a une distinction à faire entre :
- les fichiers provenant de ZCube “stables”, donc optimisé.
- les nouveaux fichiers ou fichiers non optimisées qui appartienent à un ZCube partiel.
Il y a deux paramètre de configuration pour définir ce qu’est un ZCube et ZCube partiel.
- MIN_CUBE_SIZE : Taille du ZCube pour laquelle les nouvelles données ne seront plus fusionnées avec celui-ci lors du OPTIMIZE incrémentiel. La valeur par défaut est 100 Go.
- TARGET_CUBE_SIZE : taille cible des ZCubes que nous allons créer. Il ne s’agit pas d’un maximum absolu ; nous continuerons à ajouter des fichiers à un ZCube jusqu'à ce que leur taille combinée dépasse cette valeur. Cette valeur doit être supérieure ou égale à MIN_CUBE_SIZE. La valeur par défaut est 150 Go.
Un ZCube est partiel si sa taille est plus petite que le MIN_CUBE_SIZE.
Que se passe-t-il lors du déclenchement d’un OPTIMIZE ?
Un ensemble de fichiers candidats va être sélectionnés, ils proviennent soient de :
- ZCubes partiels
- ou de nouveaux fichiers qui ont été ajoutés après
Pour les rassembler en plusieurs ZCubes, où l’algorithme de la courbe va être appliqué. Chaque ZCube créé produit un commit, ce qui permet de sauvegarder le résultat partiel en cas de crash.
Une analogie intéressante, qui illustre un peu le comportement du Liquid Clustering est que cela ressemble à une défragmentation de disque dur, on va chercher à remplir les ZCube au maximum pour éviter les petits fichiers.
Quand l’utiliser ?
De la même manière que Z-Order, il faut le faire sur des colonnes souvent utilisées comme prédicat et qui ont une haute cardinalité.
Le liquid clusturing offre surtout une flexibilité accrue par rapport au Z-Ordering, par rapport à la construction du clustering et sa maintenance, donc il conviendra mieux aux tables dont les requêtes sont voués à changer souvent, et aux tables qui grandissent vite.
Si les colonnes de clusturing changent, alors les fichiers produits et déjà optimisés précédemment avec l’ancien set de colonnes ne seront pas touchés. Seul les nouvelles données seront clusterisés avec le nouveau set de colonnes.
Cela n’est pas compatible avec le Z-Order et le Hive-Style-partitioning, pour convertir ces tables il faudra utiliser les colonnes de partitions et Z-Order comme colonnes de Liquid Clusturing.
Comme dit en début de cette section, le Liquid Clustering est encore en phase expérimentale, toutes les fonctionnalités ne sont pas encore supportés dans la version 3.1 de Delta Lake.
Pour aller plus loin
Design Doc de la fonctionnalité, documentation officielle. Un extrait de la vidéo de la Keynote d’annonce des nouveautés de Delta Lake 3.0 au Data + AI Summit, qui illustre rapidement le Liquid Clustering.
Conclusion
J’espère que vous en savez maintenant plus sur ce qu’est le Z-Ordering et le Liquid Clustering, et comment ils peuvent améliorer les performances de vos tables, Il faudra surveiller de près ce qui fait autour de ce dernier.