Il peut vous arriver lors de votre carrière que l’on vous demande de créer un fichier Excel à partir de vos données, que soit pour du reporting ou autres. Pour créer des fichiers Excel en Scala, on va devoir utiliser l’interopérabilité avec Java et utiliser une bibliothèque Java Open Source bien connue pour manipuler les fichiers Microsoft, Apache POI.
Configuration
Dans notre build.sbt il faut importer les librairies Spark et POI, ici leur dernière version à date.
libraryDependencies ++= Seq(
"org.apache.poi" % "poi" % "5.2.5",
"org.apache.poi" % "poi-ooxml" % "5.2.5",
"org.apache.poi" % "poi-ooxml-lite" % "5.2.5",
"org.apache.spark" %% "spark-core" % "3.5.1",
"org.apache.spark" %% "spark-sql" % "3.5.1"
)Pour le jeu de données que l’on va utiliser en exemple, nous allons prendre ces données Open Data de Paris https://opendata.paris.fr/explore/dataset/compte-de-resultat/information/ qui sont les comptes de résultats de la ville, l’export parquet a été utilisé.
Comment créer un fichier Excel à partir de mes données Spark ?
Pour faire cela, il n’y a pas vraiment d’autres choix que d’abord “collecter” vos données, (après agrégation ou non), et de transformer vos lignes afin de créer chaque cellule de notre fichier Excel.
Pour la création de cellules, cela se fait de manière “classique” :
- D’abord en instanciant un objet
XSSFWorkbookpour travailler avec le type de fichier .xlsx. - Ensuite nous aurons besoin d’une feuille, pour cela il faudra créer un objet
XSSFSheet, à l’aide de la méthodecreateSheetsur l’objet XSSFWorkbook. - Il vous faudra ensuite créer les lignes à partir de ce dernier avec
createRow, ce qui nous donne un objetXSSFRow. - Puis créer les cellules avec
createCellsur les objets XSSRow, ce qui donnera un objetXSSFCell. - Et enfin pour modifier le contenu de vos cellules, il faudra utiliser la méthode
setCellValue.
Pour écrire notre fichier, on utilisera la méthode write du XSSFWorkbook, qui prend en paramètre un OutputStream.
Voici un exemple de code :
import org.apache.poi.xssf.usermodel.{XSSFCell, XSSFRow, XSSFSheet, XSSFWorkbook}
import org.apache.spark.sql.{Row, SparkSession}
import java.io.{FileNotFoundException, FileOutputStream, IOException}
val spark = SparkSession.builder()
.master("local[*]")
.getOrCreate()
val compteDeResultatDf = spark.read.parquet("compte-de-resultat.parquet")
/*
compteDeResultatDf.printSchema()
root
|-- exercice_comptable: string (nullable = true)
|-- type_de_resultat: string (nullable = true)
|-- produit_charge: string (nullable = true)
|-- poste: string (nullable = true)
|-- detail_postes: string (nullable = true)
|-- montant_en_eur: double (nullable = true)
*/
//certains montants sont à null, on leur donne le montant 0 par défaut.
//et mise à négatif du montant quand son type est charges.
val dfCleaned = compteDeResultatDf
.na.fill(0, Seq("montant_en_eur"))
.withColumn("montant_en_eur",
when($"produit_charge" === "CHARGES", -$"montant_en_eur") //mise à négatif du montant quand son type est charges
.otherwise($"montant_en_eur")
)
val dataCollected = dfCleaned
.collect()
val wb: XSSFWorkbook = new XSSFWorkbook() //création du workbook
val sheet: XSSFSheet = wb.createSheet("ma feuille") //création d'une feuille dans le workbook
//Création d'un style de cellule pour les montants, ici pour obtenir 2 chiffres après la virgule dans Excel
val amountStyle= wb.createCellStyle()
amountStyle.setDataFormat(wb.createDataFormat().getFormat("0.00"))
//notre première ligne sera le header de nos données
val header = dfCleaned.columns
val headerRow = sheet.createRow(0)
for {
i <- header.indices
cell = headerRow.createCell(i)
} yield cell.setCellValue(header(i))
for {
i <- dataCollected.indices
poiRow: XSSFRow = sheet.createRow(i) //pour chaque ligne de nos données, on créé une ligne Excel, en sautant la première ligne dans l'Excel
sparkRow: Row = dataCollected(i) //on prend aussi la Row en cours
j <- 0 until sparkRow.size
cell: XSSFCell = poiRow.createCell(j) //pour chaque colonne de nos données, on créé une cellule Excel
value: Any = sparkRow(j) //on prend la valeur de la colonne en cours
} yield value match {
//Pattern matching pour éventuellement convertir certaines données,
//en effet setCellValue n'accepte que certains types en entrée.
//Ici que Double et String car le schéma de notre DataFrame ne contient que ces derniers pour l'exemple.
//On peut y ajouter du Style/Formattage selon le type auquel on match,
//ici le format qui nous permet d'avoir 2 chiffres après la virgule.
case d: Double => {
cell.setCellStyle(amountStyle)
cell.setCellValue(d)
}
case s: String => cell.setCellValue(s)
}
//pour régler la largeur de nos colonnes automatiquement, attention plus vous avez de données, plus cela est coûteux
header.indices.foreach(sheet.autoSizeColumn)
//écriture de notre fichier
val os = new FileOutputStream("workbook.xlsx")
try {
wb.write(os)
} catch {
case fnf: FileNotFoundException => fnf.printStackTrace()
case ioe: IOException => ioe.printStackTrace()
} finally {
os.close()
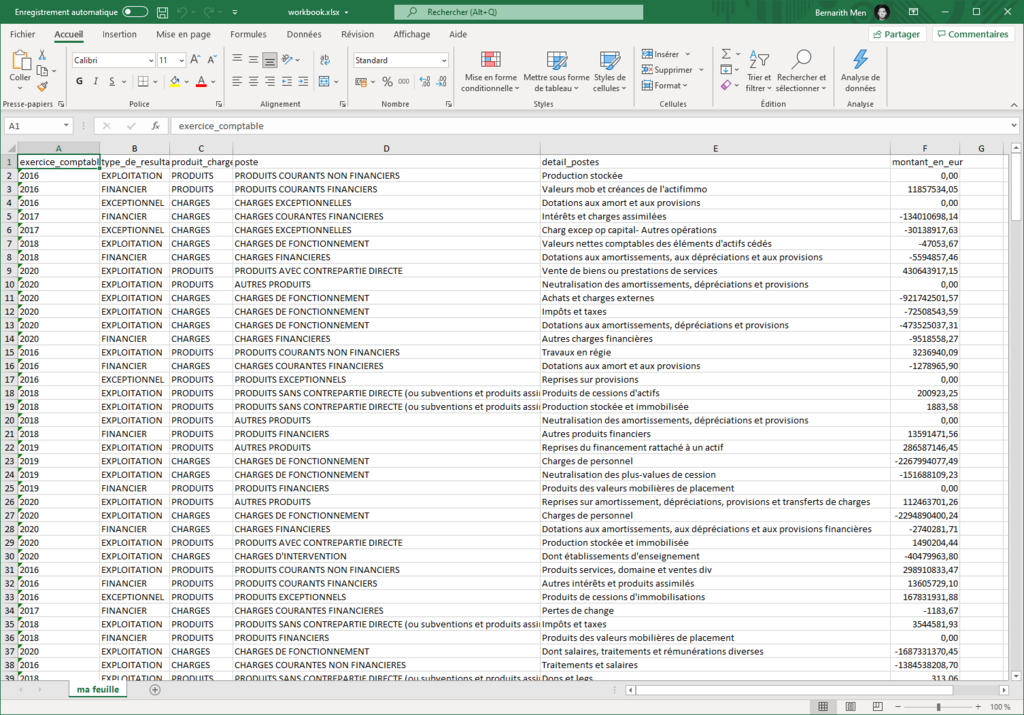
}Voici le résultat après ouverture du fichier sous Excel :
Comment faire pour créer un tableau croisé dynamique avec Apache POI ?
Maintenant que nous avons vu comment comment créer un fichier Excel à l’aide de nos données, nous allons voir comment créer un tableau croisé dynamique.
Une fois notre XSSFWorkbook instancié et rempli de données, il suffira d’utiliser la méthode .createPivotTable sur un objet XSSFSheet. La méthode prend en paramètre :
- le tableau source qui sera utilisé pour le tableau croisé dynamique, ci-dessous on utilisera un objet
AreaReferencepour indiquer la plage du tableau - la cellule qui recevra le TCD, on utilise un objet
CellReferencepour cela, la cellule est dans la feuille avec laquelle on a invoqué la méthode - en option, un object
XSSFSheet, si la source est dans une autre feuille, cela sera le cas de notre exemple
On reprend le code précédent juste avant l’écriture du fichier:
import org.apache.poi.ss.usermodel.DataConsolidateFunction
import org.apache.poi.ss.util.{AreaReference, CellReference}
import org.apache.poi.xssf.usermodel.{XSSFCell, XSSFPivotTable, XSSFRow, XSSFSheet, XSSFWorkbook}
/*
code précédent de création
*/
//on créé une nouvelle feuille qui va contenir notre TCD
val tcdSheet: XSSFSheet = wb.createSheet("TCD")
val pivotTable: XSSFPivotTable = tcdSheet.createPivotTable(
new AreaReference("A1:F288", null), //les coordonnées du tableau source, null car la méthode prend par défaut un deuxième paramètre qui est la version du spreadsheet
new CellReference("A1"), //celulle qui recevra le TCD
sheet) //on reference la feuille source optionnellement, par défaut la feuille source est celle utilisée pour invoquer la méthode createPivotTable
//Nous allons utiliser comme étiquette de lignes :
pivotTable.addRowLabel(0) //exercice_comptable -> colonne 0 de notre tableau source
pivotTable.addRowLabel(1) //type_de_resultat
pivotTable.addRowLabel(2) //produit_charge
//Nous ajoutons une colonne qui sommera les montants
pivotTable.addColumnLabel(DataConsolidateFunction.SUM, 5)
//écriture de notre fichier
val os = new FileOutputStream("workbook.xlsx")
try {
wb.write(os)
} catch {
case fnf: FileNotFoundException => fnf.printStackTrace()
case ioe: IOException => ioe.printStackTrace()
} finally {
os.close()
}On retrouve notre TCD dans la feuille “TCD” :
Comment faire pour modifier un fichier Excel déjà existant avec mes données ?
Et si nous souhaitons, mettre à jour nos données ? Imaginons que c’est une correction de montants à appliquer. Nous allons créer la case class CompteDeResultat et créer un petit Dataset de correction.
case class CompteDeResultat(
exercice_comptable: String,
type_de_resultat: String,
produit_charge: String,
poste: String,
details_postes: String,
montant_en_eur: Double
)import org.apache.poi.ss.usermodel.{Cell, Row, Sheet, Workbook, WorkbookFactory}
import org.apache.spark.sql.{Dataset, SparkSession}
import java.io.{FileInputStream, FileNotFoundException, FileOutputStream, IOException}
import scala.jdk.CollectionConverters._
//création "rapide" d'un dataset de correction de montants, cela aurait pu venir d'une table de correction
val spark = SparkSession.builder()
.master("local[*]")
.getOrCreate()
import spark.implicits._
val correctionDS: Dataset[CompteDeResultat] = List(
CompteDeResultat("2016","EXPLOITATION","PRODUITS","PRODUITS COURANTS NON FINANCIERS","Production stockée", 99999999999.0),
CompteDeResultat("2016","FINANCIER","PRODUITS","PRODUITS COURANTS FINANCIERS","Valeurs mob et créances de l'actifimmo", 55555555555.0)
).toDS
/*
correctionDS.printSchema()
root
|-- exercice_comptable: string (nullable = true)
|-- type_de_resultat: string (nullable = true)
|-- produit_charge: string (nullable = true)
|-- poste: string (nullable = true)
|-- detail_postes: string (nullable = true)
|-- montant_en_eur: double (nullable = false)
*/Utilisons le fichier que nous avons précédemment créé, l’idée est que nous connaissons déjà son schéma, sa structure ne changera pas, donc nous savons comment le lire, c’est à dire que le code que l’on va définir sera assez spécifique à notre fichier Excel, ici on sait que c’est le montant que l’on veut modifier.
On va créer deux Map :
- À partir du fichier Excel, une qui associe toutes les colonnes (hors colonnes à modifier) aux coordonnées des cellules à modifier
- À partir de notre dataFrame, une Map qui aura la même clé et qui associe la nouvelle valeur
Pour créer ces Maps, nous définirons ces méthodes :
def getMapFromWorkbook(wb: Workbook, sheetName: String, columnToModify: String): Map[List[String], (Int, Int)] = {
val sheet: Sheet = wb.getSheet(sheetName)
//on récupère du header, l'index des colonnes à exclure
val headerRow = sheet.getRow(0)
val columnIndexToExcludeFromKey = headerRow.cellIterator().asScala.toList
.find(cell => cell.getStringCellValue == columnToModify)
.map(_.getColumnIndex)
.getOrElse(-1)
//création de la Map qui associe chaque clé aux coordonnées des cellules à modifier
(for {
row: Row <- sheet.rowIterator().asScala.toList.tail
cells: List[Cell] = row.cellIterator().asScala.toList.filterNot(_.getColumnIndex == columnIndexToExcludeFromKey)
} yield cells.map(_.getStringCellValue) -> (row.getRowNum, columnIndexToExcludeFromKey)
).toMap
}
/*extrait de la Map après execution
HashMap(
List(2021, EXPLOITATION, CHARGES, CHARGES D'INTERVENTION, Dont autres organismes publics) -> (212,5),
List(2019, FINANCIER, CHARGES, CHARGES FINANCIERES, Charges nettes sur cessions de valeurs mobilières de placement) -> (44,5),
...)
*/
def getMapFromDataset(ds: Dataset[CompteDeResultat]): Map[List[String], Double] = {
ds.collect
.map(row => List(
row.exercice_comptable,
row.type_de_resultat,
row.produit_charge,
row.poste,
row.details_postes
) -> row.montant_en_eur
).toMap
}
/*extrait de la Map
Map(List(2016, EXPLOITATION, PRODUITS, PRODUITS COURANTS NON FINANCIERS, Production stockée) -> 9.99999999E8,
List(2016, FINANCIER, PRODUITS, PRODUITS COURANTS FINANCIERS, Valeurs mob et créances de l'actifimmo) -> 5.55555555E8)
*/Pour lire un Excel avec POI, on utilise un FileInputStream et POI propose un WorkbookFactory qui nous permet d’obtenir un Workbook à partir de l’input stream.
On fait ensuite correspondre les deux Maps pour appliquer les modifications, enfin on écrit le workbook dans un autre fichier Excel new_workbook.xlsx.
val inp = new FileInputStream("workbook.xlsx") //lecture de notre Excel
try {
val wb: Workbook = WorkbookFactory.create(inp) //création d'un objet workbook à partir de la bibliothèque
val mapWB = getMapFromWorkbook(wb, "ma feuille", "montant_en_eur")
val mapDS = getMapFromDataset(correctionDS)
val sheet = wb.getSheet("ma feuille")
//modifications des cellules à partir des deux Maps
for {
modifications: (List[String], Double) <- mapDS
coordinates: (Int, Int) = mapWB(modifications._1)
row = sheet.getRow(coordinates._1)
cell = row.getCell(coordinates._2)
} yield {
cell.setCellValue(modifications._2)
}
//écriture de notre fichier sous le nom new_workbook.xlsx
val os = new FileOutputStream("new_workbook.xlsx")
try {
wb.write(os)
} catch {
case fnf: FileNotFoundException => fnf.printStackTrace()
case ioe: IOException => ioe.printStackTrace()
} finally {
os.close()
}
} finally if (inp != null) inp.close()Sur le nouveau fichier nous voyons bien les deux lignes modifiées (en surbrillance sur la capture) :
Sur le TCD, on a bien les valeurs à jour aussi :
Conclusion
Nous avons vu comment créer un modifier un fichier Excel à partir de nos données Spark avec Apache POI, avec un focus sur son module XSSF permettant de créer des .xlsx, et avec un exemple sur comment créer un tableau croisé dynamique, je vous invite à regarder sa documentation officielle https://poi.apache.org/components/spreadsheet/how-to.html.