Le traitement
Nous avons en entrée une structure comme celle-ci
{
"id": "1234",
"created": "2021-01-01T00:00:00",
"criteriaA_periods": [
{ "begin": "2021-01-03T00:00:00", "end": "2021-01-05T00:00:00" },
{ "begin": "2021-01-07T00:00:00", "end": "2021-01-08T00:00:00" },
],
"criteriaB_periods": [],
"criteriaC_periods": [],
"criteriaD_periods": [
{ "value": 12,
"begin": "2021-01-02T00:00:00", "end": "2021-01-05T00:00:00" }
],
}Elle contient des périodes d'application de divers critères A, B, C, et D. En période d'application, on utilise la valeur 1, sinon c'est 0. Pour le critère D, en période d'application on utilise la valeur fournit dans le critère, sinon c'est une valeur par défaut.
Par transformation Spark, on veut une structure plus linéaire qui au 1er janvier 2021 ressemble à
{
"id": "1234",
"created": "2021-01-01T00:00:00",
"applicationDatetime": "2021-01-01T00:00:00",
"criteriaA_availability": [ 0, 0, 1, 1, 1, 0, 1, 1],
"criteriaB_availability": [ 0, 0, 0, 0, 0, 0, 0, 0],
"criteriaC_availability": [ 0, 0, 0, 0, 0, 0, 0, 0],
"criteriaD_availability": [30, 12, 12, 12, 12, 30, 30, 30],
}Dans la structure de sortie, chaque critère contient une liste dans laquelle l'indice (commençant à 0) représente le décalage par rapport à un jour donné (ie. l'indice 0 correspond à J, 1 à J+1, 2 à J+2...).
Les données d'entrée sont stockées dans une base et nous devons utiliser Spark pour les récupérer, calculer la nouvelle structure et les intégrer dans une partie d'un autre traitement Spark.
Deux solutions s'offrent à nous avec Spark SQL : API SQL ou API fonctionnelle. Et il y a une contrainte : c'est du Spark 2.2.
Avec l'API SQL
J'ai l'habitude de penser que par défaut il faut utiliser Spark SQL et les fonctions que fournit le module. Ainsi, nous pouvons bénéficier des optimisations proposées par Catalyst, sachant qu'il y a de fortes chances que Catalyst se débrouille mieux que nous pour obtenir des jobs performants.
Le code récupéré permettant de résoudre le problème présenté ici est en effet basé sur l'API SQL de Spark SQL. Sur un problème qui semble linéaire, je me suis retrouvé avec des requêtes Spark SQL utilisant des explodes, divers filtres et des jointures effectuées sur le même datasource. Le DAG de la requête est assez monstrueux, avec 5 scans (LocaTableScan) des mêmes données !
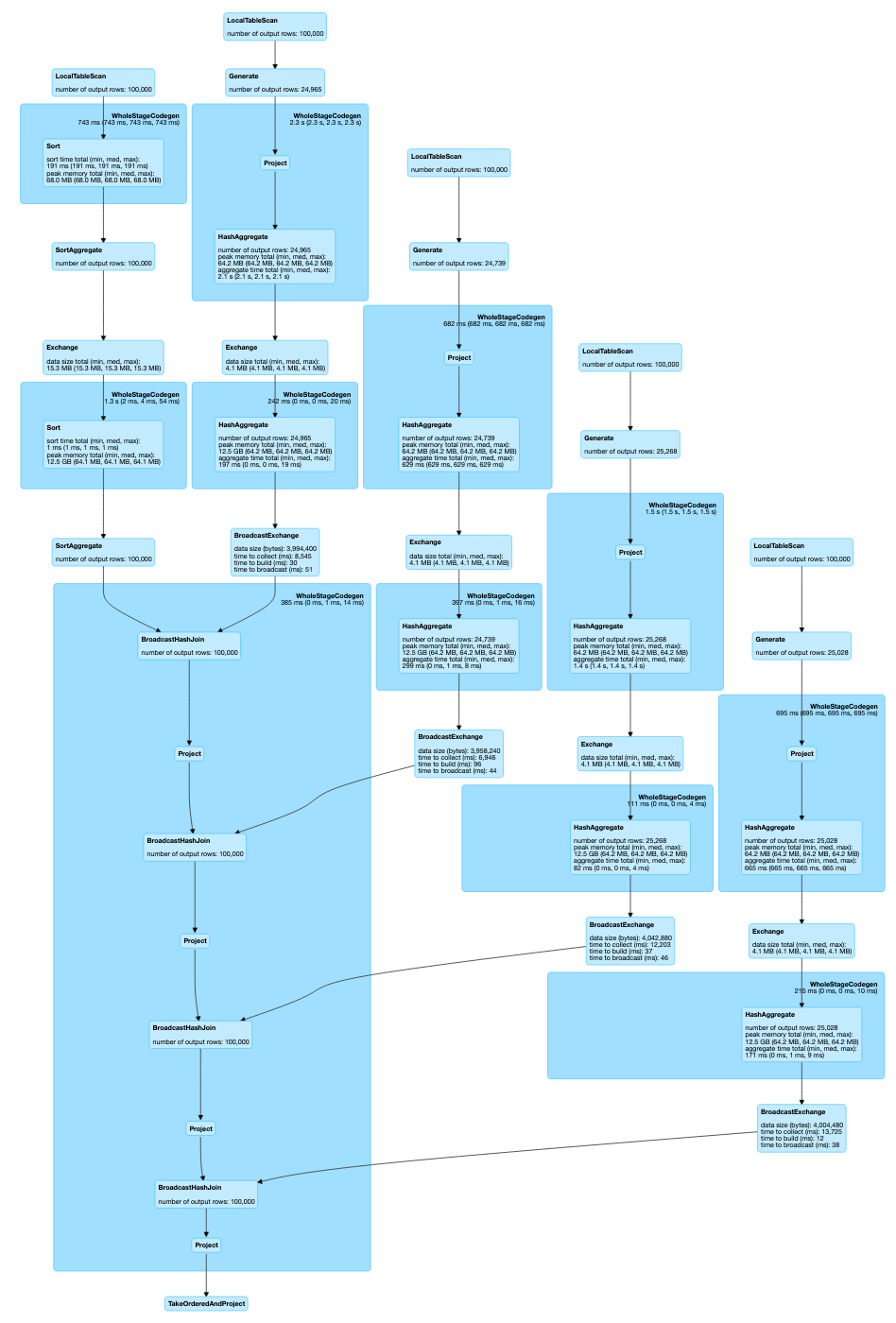
On a un total de 5 jobs et 10 stages.
La base du calcul est représentée par cette fonction qui pour chaque critère (représenté par la colonne en paramètre) va créer un array de flag.
def availability(dataset: DataFrame,
criteriaColumn: Column,
dayCount: Int,
currentDate: String,
value: Option[Int],
defaultValue: Int): DataFrame =
(0 to dayCount)
.foldLeft(dataset.withColumn("interval", explode(criteriaColumn))) {
case (ds, i) =>
ds.withColumn(s"int_$i",
when(
date_add(lit(currentDate), days=i)
.between($"interval.begin", $"interval.end"),
value
.map(c => col(s"interval.$c"))
.getOrElse(1)
).otherwise(defaultValue)
)
}
.groupBy("id")
.agg(array(
(0 to dayCount).map { i => max(s"int_$i") }: _*
) as "ints")Cette fonction est donc appelée 4 fois (1 fois par critère) sur le même dataframe. Chaque appel fournit un dataframe. Ces dataframes sont ensuite regroupés par des jointures successives basées sur l'id. Un filtrage est aussi réalisé sur le dataframe de base. On arrive ainsi à 5 scans !
L'une des raisons de cette complexité est due au fait que l'API SQL de Spark SQL ne permet pas de travailler finement sur les données prises lignes par lignes, sauf à utiliser éventuellement des UDF. Ça ne veut pas dire que cette approche est mauvaise. Sur des requêtes ayant des formes plus classiques (du simple SELECT à une série de jointures sur des formats divers impliquant des transformations usuelles de colonnes) Spark SQL aura probablement de meilleures performances que ce que vous pourrez faire avec Spark Core ou l'API fonctionnel des Datasets. Le problème ici n'est pas classique d'un point de vue Spark SQL et l'effet est à peu près le même que d'utiliser une formule 1 sur de l'herbe : ça ne va pas aller très vite parce que ce n'est pas prévu pour ça.
Vers l'API fonctionnelle
Réfléchissons en se demandant comment faire si nous n'avions pas Spark sous la main ?
Réponse : on parcourrait les données en une passe. Pour chaque donnée rencontrée on ferait une conversion de la structure d'entrée en structure de sortie sans faire appel à des données externes à part d'éventuels paramètres intégrés au traitement. Si on veut accélérer les choses on peut même partitionner les données en fonction du nombre de machines et de cœurs mis à disposition. On a ainsi un traitement linéaire et plutôt simple.
Si on revient à Spark, on peut récupérer les données au sein d'un dataset et faire appel à la fonction map. Spark s'occupera ensuite du partitionnement, de la parallélisation et la distribution du traitement.
Résultat : un seul job avec un seul stage et un beau DAG bien linéaire !
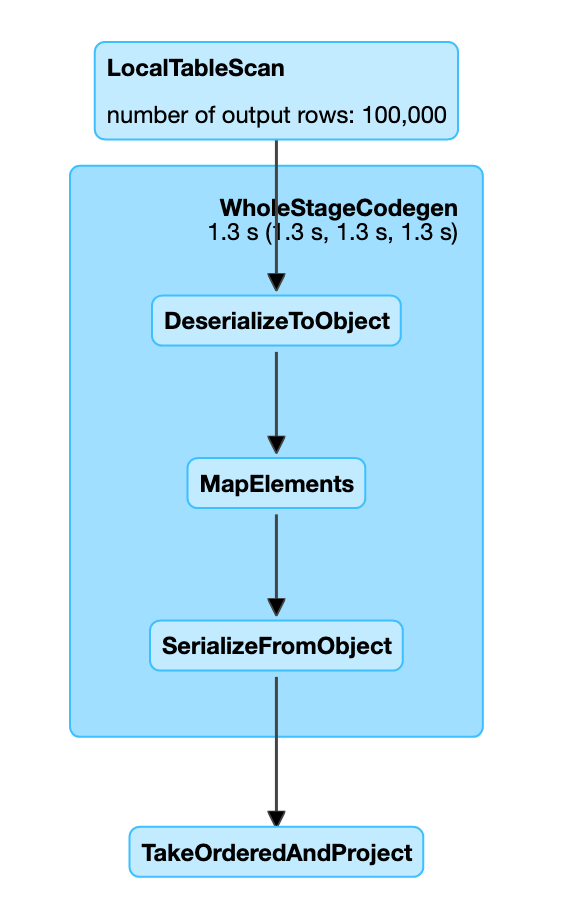
Son DAG indique que les données ne sont parcourues qu'une seule fois. Les 100 000 lignes sont traitées en 1,3 secondes (sur ma machine) avec en extrémité des phases de sérialisation. On peut regarder dans le détail
Dans le graphique ci-dessous, les phases de scheduler delay et de serde représente un overhead de ~350 ms contre 1 seconde de traitement (toujours sur ma machine).


Le principe de la solution consiste d'abord à convertir chaque ligne sous la forme d'une case class appropriée sous la forme dataframe.as[MyCaseClass]. La conversion linéaire est ensuite réalisée en faisant un map sur le dataset, qui permettra d'obtenir pour chaque ligne une case class correspondant au schéma attendu en sortie.
Chaque période est d'abord convertit en WeightedPeriod, dont le poids vaut 1 pour les critères A, B et C.
case class WeightedPeriod(weight: Int,
begin: LocalDateTime,
end: LocalDateTime) {
def contains(ts: LocalDate): Boolean =
(begin.equals(ts)
|| end.equals(ts)
|| (ts.isAfter(begin) && ts.isBefore(end)))
}Puis les périodes des critères sont transformées en tableau de flags avec cette méthode
def availability(periods: Seq[WeightedPeriod],
dayCount: Int,
current: LocalDateTime,
defaultValue: Int): Seq[Int] =
(0 to dayCount)
.map { deltaDay =>
val offsetDay = current.plusDays(deltaDay)
periods.find(_.contains(offsetDay))
.map(_.weight)
.getOrElse(defaultValue)
}Ce qui donne
dataframe
.as[InputEntity]
.map(input => OutputEntity(
id = input.id,
created = id.created,
criteriaA_availability = availability(id.criteriaA_periods.map(_.withWeight(1), dayCount, currentDateTime, defaultValue=0),
criteriaB_availability = availability(id.criteriaB_periods.map(_.withWeight(1), dayCount, currentDateTime, defaultValue=0),
criteriaC_availability = availability(id.criteriaC_periods.map(_.withWeight(1), dayCount, currentDateTime, defaultValue=0),
criteriaD_availability = availability(id.criteriad_periods.map(_.toWeight, dayCount, currentDateTime, defaultValue=defaultD),
))Conclusion
Spark SQL est un outil formidable, permettant de réaliser simplement des traitements complexes et avec un niveau d'optimisation difficile à obtenir à la main. Néanmoins, l'API SQL de ce framework ne doit pas nous faire oublier qu'il faut analyser ce qu'il se passe lorsqu'on envoie nos requêtes à Spark. Car cette API n'est pas adaptée à tous les cas. Il est des cas où elle peut être plus une lourdeur qu'un véritable atout. Il faut dans ce cas ne pas hésiter à utiliser des UDF ou alors à se rapprocher de l'API fonctionnelle afin de retrouver des performances raisonnables. Car Spark reste néanmoins l'un des frameworks les plus performants pour ce qui concerne les traitements Big Data (qu'il faut bien comprendre comme de la donnée éparpillée sur un cluster, trop volumineuse pour tenir sur une seule machine) avec une API relativement confortable.
Ceci dit, nous sommes en Spark 2.2 dans ce REX. Ce qui signifie que cette conclusion est à édulcorer. Sachant que les versions plus récentes de Spark permettent d'intégrer des fonctions d'ordre supérieur dans les requêtes SQL, il serait possible d'exprimer simplement une solution à ce problème dans une requête.
Photographie par Laura Ockel sur Unsplash.