Il est parfois nécessaire de prendre des données qui viennent de sources différentes et de les combiner en une seule source. En SQL, pour ça nous utilisons UNION ou UNION ALL.
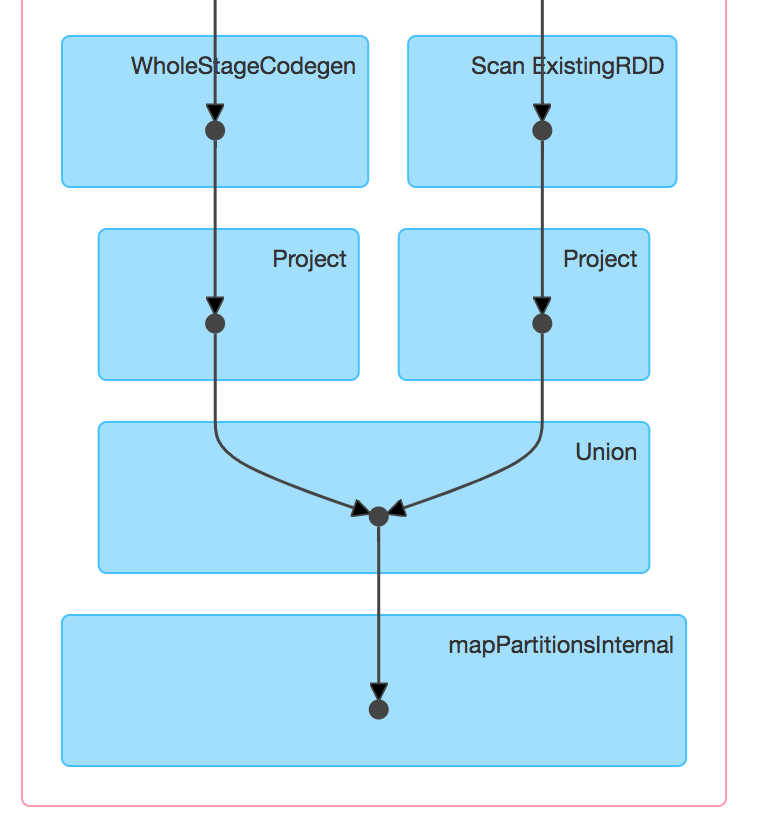
En Spark, nous pouvons faire de même. Néanmoins, cela ne marche pas toujours comme nous le pensons. L'union en Spark df1.union(df2) a le même comportement qu'en SQL, ce qui peut poser des interrogations lorsque l'on utilise les datasets (le mode "typé-scala" de Spark) : le code compile, mais nous pouvons nous retrouver avec une erreur au runtime (dans le driver) ou pire, avec une erreur silencieuse pour les plus chanceux.
En exemple
Nous allons manipuler des données qui ressemblent à A (avec deux champs b et c).
case class A(b: String, c: Long)Créons deux Dataset[A].
val ds1 = smallDs(A("1", 2), A("3", 4))Ici smallDs, qui derrière fait appel à session.sparkContext.parallelize(data, 1).toDS. Un show sur ds1 donne :
+---+---+
|b |c |
+---+---+
|1 |2 |
|3 |4 |
+---+---+Voici le deuxième dataset.
val ds2: Dataset[A] = dfFromJson("{b:'5',c:6, d:7}", "{b:'8',c:9, d:10}").as[A]+---+---+---+
|b |c |d |
+---+---+---+
|5 |6 |7 |
|8 |9 |10 |
+---+---+---+Nous pouvons noter déjà que ds2 n'a pas le même schéma que ds1 alors qu'il sont du même type. Si nous demandons à Spark de lire de la donnée et de nous retourner un type A en Scala, il vérifie juste si c'est possible de le faire au moment venu.
Par contre, si nous tentons l'union entre les deux datasets, cela ne va pas passer.
assertDsEqual(ds1.union(ds2), A("1", 2), A("3", 4), A("5", 6), A("8", 9))Union can only be performed on tables with the same number of columns, but the first table has 2 columns and the second table has 3 columnsUne façon assez simple de régler le problème, dans ce cas spécifique, consiste d'enlever le champ en trop dans ds2.
val ds3: Dataset[A] = ds2.drop("d").as[A]
assertDsEqual(ds1.union(ds3), A("1", 2), A("3", 4), A("5", 6), A("8", 9))Ça marchera, mais sans que nous n'ayons de véritable garantie sur l'ordre des champs restants.
Par exemple, si on tente ceci :
val ds3: Dataset[A] = ds2.select("c","b").as[A]
assertDsEqual(ds1.union(ds3), A("1", 2), A("3", 4), A("5", 6), A("8", 9))ça compile, mais on se retrouve avec une erreur dans le driver :
Cannot up cast `c` from string to bigint ...Néanmoins, si les datasets ont déjà le même nombre de champ, nous pouvons utiliser unionByName (depuis Spark 2.3.0) :
val ds3: Dataset[A] = ds2.drop("d").as[A]
assertDsEqual(ds1.unionByName(ds3), A("1", 2), A("3", 4), A("5", 6), A("8", 9))Réglons le problème définitivement
Les opérateurs d'union existant sur les datasets ne sont pas suffisants aujourd'hui pour aligner des schémas. Ils nécessitent trop de manipulations manuelles.
En fait, ce que nous souhaitons, c'est une fonction de la forme :
def betterDatasetUnion[A](ds1:Dataset[A],ds2:Dataset[A]):Dataset[A]
Pour cette implémentation, nous allons nous baser sur le schéma de A, qui se récupère assez facilement via un Encoder[A], membre de Dataset[A].
val schema:StructType = ds1.exprEnc.schemaLe schéma nous donne les champs disponibles en utilisant schema.fieldnames. Ce sont en fait les champs de la case classe A.
val fieldnames = schema.fieldnamesNous pouvons ensuite filtrer les dataframes avec les champs de la case class avant d'utiliser unionByName.
ds1.select(fieldnames).unionByName(ds2.select(fieldnames))Moyennant quelques détails d'implémentations :
exprEncest privé, nous utilisons alors un implicit pour le récupérer même s'il est déjà présent dansds1,selectprend une liste de colonne.
def datasetUnion[A: Encoder](ds1: Dataset[A], ds2: Dataset[A]): Dataset[A] = {
val exprEnc: Encoder[A] = implicitly[Encoder[A]]
val name :: names = exprEnc.schema.fieldNames.toList
ds1.select(name, names:_*).union(ds2.select(name, names:_*)).as[A]
}Cette fonction nous permet de faire directement datasetUnion(ds1, ds2) sans autres manipulations.
La suite
Malheureusement, cela ne marche pas complètement, dès que nous utilisons des structures complexes, nous avons des erreurs comme celle-ci :
Union can only be performed on tables with the compatible column types. array<struct<b:string,c:bigint,d:bigint>> <> array<struct<b:string,c:bigint>> at the first column of the second table;;Par exemple, si nous utilisons la case class E ci-dessous :
case class E(as: Seq[A], f: String)
val e1 = E(Seq(A("1", 2)), "3")
val ds1: Dataset[E] = smallDs[E](e1)
val ds2: Dataset[E] = dfFromJson("{as:[{b:'5',c:6, d:7}, {b:'8',c:9, d:10}],f:'11'}").as[E]
val res: Dataset[E] = datasetUnion(ds1, ds2)Pour aller plus loin, nous pouvons utiliser ce que nous avons fait dans schema-utils, qui permet d'aller beaucoup plus loin et d'aligner une dataframe / dataset sur un schéma existant :
def deepUnion[A:Encoder](ds1:Dataset[A], ds2:Dataset[A]):Dataset[A] = {
import io.univalence.schemautils.AlignDataframe
val schema = implicitly[Encoder[A]].schema
AlignDataframe(ds1,schema).union(AlignDataframe(ds2,schema)).as[A]
}ou
def deepUnion(ds1:Dataset[A], ds2:Dataset[A]):Dataset[A] = {
import io.univalence.schemautils.AlignDataset
AlignDataset(ds1).union(AlignDataset(ds2))
}(Schema-utils utilise Spark 2.4. Néanmoins, cette manipulation est possible en Spark 1.6 ou en Spark 2.x, la version 2.4 est par contre beaucoup plus efficace.)
Conclusion
Ce genre de problème n'est pas forcément complexe à résoudre, néanmoins cela rend l'utilisation de Spark moins intuitive.
Au Paris Scala User Group de septembre, Raphaël Luta et Choucri Fahed nous avaient fait un retour sur certains des problèmes qu'ils ont rencontrés en utilisant Spark au jour le jour, dont celui que nous venons de voir (union sur les RDD vs Dataset).
En attendant que la vidéo soit disponible sur la chaîne Youtube du user group, les slides de cette session sont disponibles :
 https://drive.google.com/file/d/1dAkhMzk5UGzS0AmcyTxI5Fc_dR4PvqvV/view
https://drive.google.com/file/d/1dAkhMzk5UGzS0AmcyTxI5Fc_dR4PvqvV/view
 https://www.meetup.com/paris-scala-user-group-psug/events/254988502/
https://www.meetup.com/paris-scala-user-group-psug/events/254988502/ https://www.youtube.com/channel/UCzRgovSmXzR2exnlWrawesA/featured?cbrd=1&ucbcb=1
https://www.youtube.com/channel/UCzRgovSmXzR2exnlWrawesA/featured?cbrd=1&ucbcb=1Raphaël Luta
https://twitter.com/raphaelluta
Choucri FAHED